What Achilles Said to the Tortoise About Binding-Affinity Prediction
March 3, 2025This post is an attempt to capture some thoughts I have about ML models for predicting protein–ligand binding affinity, sequence- and structure-based approaches to protein modeling, and what the interplay between generative models and simulation may look like in the future. I have a lot of open questions about this space, and Abhishaike Mahajan’s recent Socratic dialogue on DNA foundation models made me curious to try the dialogue format here.
(With apologies to Lewis Carroll and Douglas Hofstadter.)

[The TORTOISE is sitting on a park bench with a thermos of tea and a stack of papers beside him. Enter ACHILLES, holding a stack of papers.]
ACHILLES: Hello, Mr. T. Mind if I join you on your bench?
TORTOISE: Of course, Achilles. What are you reading on this fine spring day?
ACHILLES: Right now, I’m reviewing some recent literature on the economics of seating in Mongolian yurts. And yourself?
TORTOISE: I’m looking through two fascinating papers criticizing modern protein–ligand co-folding methods.
The first is by Matthew Masters and co-workers and is entitled “Do Deep Learning Models for Co-Folding Learn the Physics of Protein–Ligand Interactions?” The authors show that AlphaFold 3 predicts the “correct” binding site for a variety of complexes even when the entire binding site is mutated to glycine, when bulky residues are added to fill the binding pocket, or when the polarity of key interactions is reversed. The authors argue that this demonstrates that AlphaFold is overfit to specific protein families, and that models need to be validated on “their compliance with physical and chemical principles.”
ACHILLES: Interesting, but not surprising.
TORTOISE: The second is by Peter Škrinjar and co-workers and is entitled “Have protein–ligand co-folding methods moved beyond memorization?” Here, the authors show that the success rate of co-folding methods is dictated by the similarity of structures to the training set. The models appear to perform well in cases where there is high train–test similarity, but on truly different structures their performance is dismal. The authors’ conclusion is even stronger than that of the first paper:
Incorporating physics-based terms to more accurately model protein-ligand interactions, potentially from simulations, conformational ensembles, or other sources, are likely needed to achieve more exciting results in this field.
Taken together, it’s clear that pure deep-learning-based approaches to solving these important scientific problems are doomed to fail.
ACHILLES: Well, let’s not rush ahead too quickly—perhaps we’ve been spending too much time together. It’s not surprising that these structure-based methods are prone to overfitting, but I expect that the next generation of sequence-only methods will overcome these hurdles.
TORTOISE: Hm, I admit this intuition leaves me in the dust. Can you enlighten me as to why your response to unphysical overfitting is to reject one of the only physical descriptors that we have—the 3D structures of the protein and the ligand? It seems to me that reducing the amount of available data is a peculiar way to improve the performance of one’s model.
ACHILLES: Of course, I’m happy to explain. Consider the problem from first principles. It’s not surprising that using 3D structures leads to overfitting—the dimensionality of these problems is vast, and our datasets are comparatively miniscule. So any given set of coordinates is virtually a guaranteed fingerprint for a particular protein or ligand, and we’re just training models that have one-hot encoded the structures they’ve seen. See for instance the recent work of Jain, Cleves, and Walters arguing that DiffDock is simply a fancy lookup table.
TORTOISE: Of course I agree, which is why it’s important that we find ways to generate more training data, not jettison what little data we have. The problem is not intractable; it seems that DiffDock-L is superior at this task. We need only wait for another order-of-magnitude increase in the amount of training data available to arrive at a robust deep-learning-based docking method.
ACHILLES: But, if you will, follow me a little further down this line of thinking. We know that protein–ligand structures are but a single snapshot of a dynamic ensemble of possibilities that interconvert smoothly in solution. This is why attempting to guess the binding affinity from a single pose is so futile, and why extensive sampling is needed for free-energy methods like FEP or TI.
Protein–ligand co-folding models must labor under the same constraints. Just because we’ve changed the scoring function from a forcefield to a neural network doesn’t mean that we can go back to considering a single averaged pose—let alone whatever pose happened to crystallize out of solution best. No, any method predicated on considering just a single pose is doomed to fail.
TORTOISE: So your proposal is to disregard all poses, and hope that “machine learning” can just call the right answer from the vasty deeps? I fear that you’ve been spending too much time on LinkedIn, my dear friend. Perhaps it’s time for you to return to a time before computing, like 5th-century Greece.
ACHILLES: Au contraire, tortuga. We know that it’s possible to go from sequence to structure with machine learning, unless you’ve already forgotten about this year’s Nobel Prize. And others have shown you can generate structural ensembles this way—look at AlphaFlow, or BioEmu. One could imagine running these models to generate candidate structures, then feeding these structures into a docking model, then feeding the docked structures into a scoring model, then combining the scoring predictions to generate a single predicted binding affinity.
TORTOISE: I agree in principle, provided each of these models can be benchmarked and verified to follow proper thermodynamic and statistical mechanical principles. But creating a perfect Boltzmann generator won’t be easy; and methods that do not reproduce the canonical ensemble lead to pathological failures in practice.
ACHILLES: Precisely! Many of these intermediate models are difficult to train, since we don’t have good ground truth for protein structural ensembles or individual binding affinities per pose. In fact, almost the only piece of data we can reliably acquire data for is the very task we want to predict—macroscopic protein–ligand binding affinity. So the entire problem becomes far more tractable if we simply combine the individual models into one end-to-end model so that we can backpropagate through the entire stack. Then we can scale to larger datasets that don’t have associated structural information, like DNA-encoded libraries or Terray’s microarray technology.
Thus, by combining the models into one, we at once simplify our task and make it possible to scale to much larger datasets: e pluribus unum.
TORTOISE: A surprisingly plausible vision, but I’m still not convinced. (And you ought to be speaking Greek, not Latin.)
Partitioning this problem into multiple models, each of which performs a defined task, means that there are verifiable, low-dimensional intermediate states that can be inspected. Structural ensembles can be saved to PDB files, and individual binding affinities can be sanity-checked. When we dump everything together into one massive mega-model, who knows what the model will try to do? These low-dimensional checkpoints might even be critical for giving us the right inductive bias to prevent overfitting.
By way of comparison, consider LLMs—we use textual checkpointing all the time, from chain-of-thought to retrieval-augmented generation. “Just train a model to do the entire task in a single pass” sounds like the accelerationist, AI-informed position, but in reality interpretability and modularity have proven to be valuable levers across many fields of machine learning. Gleefully jettisoning them hardly seems prudent.
ACHILLES: Perhaps. But forcing a model to go through a certain intermediate state only makes sense when that intermediate state is actually relevant to the task at hand. How will structure-based methods handle intrinsically disordered proteins?
TORTOISE: Even disordered proteins must have a structure.
[Enter CRAB.]
CRAB: Hullo, dear friends! Are we talking about ESM2? I fear that these methods are passé; if you haven’t heard yet, ascribing individual importance to mere proteins is an inadequate assumption now obsoleted by deep learning.
ACHILLES: Whatever do you mean?
CRAB: Exactly what I said! Proteins don’t exist in a vacuum—they possess different post-translational modifications, they aggregate, they float in and out of biomolecular condensates, and many of the most important cellular functions don’t even involve proteins.
ACHILLES: You’re correct, of course, but it’s clear that proteins are one of the key structural and functional elements of the cell. How else do you explain the history of successful therapeutics that target specific proteins?
CRAB: Selection bias, my dear friend. Of course the brute-force medicinal chemistry strategies of yesteryear managed to identify a handful of indications amenable to single-protein therapies, just like a handful of traits can be ascribed to single genes. But most traits that matter are polygenic, and most diseases are doubtless treatable only at the systems-biology level. Any lesser approximations are simply inadequate.
TORTOISE: Oh dear, I fear this is becoming a bit too much for me.
CRAB: I’ve just accepted a position at a biotech company personally backed by the high suzerains of artificial intelligence. We take millions of brightfield images of cells that have been exposed to different molecules and use deep learning to connect the observed cell-state modifications to molecular structure. Think phenotypic screening, but grander and more glorious.
ACHILLES: Now I feel out of my depth. Perhaps Mr. T is right and this new world is not for me. The 5th century does have a certain rustic charm…
TORTOISE: Wait, I think I understand. Previously, we discussed how, by training a single model, we could circumvent the need for explicitly generating protein structural ensembles and scoring individual docked poses—a single meta-model could implicitly perform all these tasks in an end-to-end differentiable fashion and simply learn all the patterns, or perhaps perform some more advanced and less constrained form of logic. Achilles, do you consider this a fair summary of your position?
ACHILLES: Yes, that seems fair enough, although I hardly see how my proposal connects to this outlandish suggestion.
TORTOISE: If we wanted to extrapolate this to entire cells, we could perform a similar exercise. We could enumerate all the proteins in the cell with all their various post-translational modifications, and then use Achilles’s model to score a given molecule’s interaction with all of them. It would be a mighty amount of work—but, in theory, it’s possible.
CRAB: Ah, but you’d still be neglecting the effects of environment, aggregation, and so on. Think of an E3 ligase—do you think you could model that one protein at a time? And what do you say to DNA, RNA, lipids, and so on and so forth.
TORTOISE: Touché. Perhaps “protein” is the wrong word here—but there must be some number of defined, localized structural entities in the cell which interact with an exogenous small molecule, and these entities must be at least somewhat separable per the principle of locality.
ACHILLES: Yes, that’s right. After all, a molecule can only be at one place at a time.
TORTOISE: So if we could use Achilles’s model to predict the interaction of the small molecule with each of these entities, we would have a sort of interaction fingerprint in entity space. We could then, with sufficient data, train a new model to learn the interaction network between each entity and predict an overall cell-level response. Do you agree, Mr. Crab?
CRAB: I suppose so, although it sounds ungainly. How exactly do you plan to study the effects of a bunch of small molecules on a particular region of chromatin?
TORTOISE: Ah, but this is where we use Achilles’s trick once more. Instead of learning one model that accounts for per-entity interactions, and another model that combines the individual per-entity predictions into a cell-level prediction, we can just learn a single model and backpropagate through the entire stack. So now our single foundation model is implicitly learning not only protein conformational ensembles, protein–ligand docking, docking rescoring—we’re also learning post-translational modifications, systems biology, and so on.
ACHILLES: Ah, now I see. Our aquatic colleague here is taking my same logic a step further—instead of implicitly learning individual structures in the course of predicting a protein–ligand interaction, he’s implicitly learning individual protein–ligand interactions in the course of predicting a single cell response.
TORTOISE: Exactly. The question then becomes if he’ll have enough data to learn the entire stack, or if his model will suffer the same overgeneralization problems as today’s protein–ligand interaction models.
ACHILLES: Right. It’s clear that at some scale, questions of information theory must predominate—every problem has some minimum amount of data that it takes to solve. Otherwise we’d all be able to solve drug toxicity just from the 1500 structures in the ClinTox dataset.
TORTOISE: Precisely. We could imagine such a strategy working at the infinite-data limit, but in practice the mismatch between problem complexity and data availability seems vast, and slow to fill.
CRAB: This has been an interesting philosophical aside, but I’m afraid that trying to cram your preconceived notions about biological dogma into my model is ill-advised. Today’s scientists think of proteins because that’s all they know how to study—but true biological understanding can only come when we’re able to learn directly on cellular data without the foolish assumptions that have plagued biochemistry to date. Trying to interpret my cell-level models through the viewpoint of proteins is like trying to decompose a Cybertruck into a linear combination of horses.
But in any event, I must be off. An army of H100s awaits me, and I must deploy them!
[Exit CRAB.]
ACHILLES: That fellow has no scientific humility. Of course proteins are important! These Silicon-Valley types have no respect for the deep biological body of knowledge that came before them, and think they can just pour images and SMILES strings into a transformer and “solve biology.” But we’d better return to our previous discussion, or things may become too recursive.
TORTOISE: There seem to be more and more fellows like him around these days... but I suppose carcinization is a well-documented phenomenon. Where were we before this unexpected conversational loop?
ACHILLES: I was just proposing the idea that sequence-based models will implicitly learn structure where it’s helpful.
TORTOISE: Ah, yes. I am beginning to catch up with your lightning-fast intuition. Are you opposed to structure for ideological reasons, or because you think structural information will never be achievable on the scale required to solve this problem?
ACHILLES: Both—I’m opposed to structure because accurate structural ensembles, which are what’s needed here, will never be available. Even a billion cryoEM structures won’t be enough because single ground-state snapshots will never be enough.
TORTOISE: But you must concede that, for instance, molecular dynamics could provide a way to generate relevant structural information under non-ground-state conditions.
ACHILLES: I freely admit that the Platonic ideal of MD simulations might furnish us with such data, to run the risk of sounding overly Greek. But you know as well as I do that MD simulations are unreliable and provide data that’s far worse than crystallography. What makes you think that dumping millions of AMBER trajectories into an ML model will do anything except increase demand for H100s?
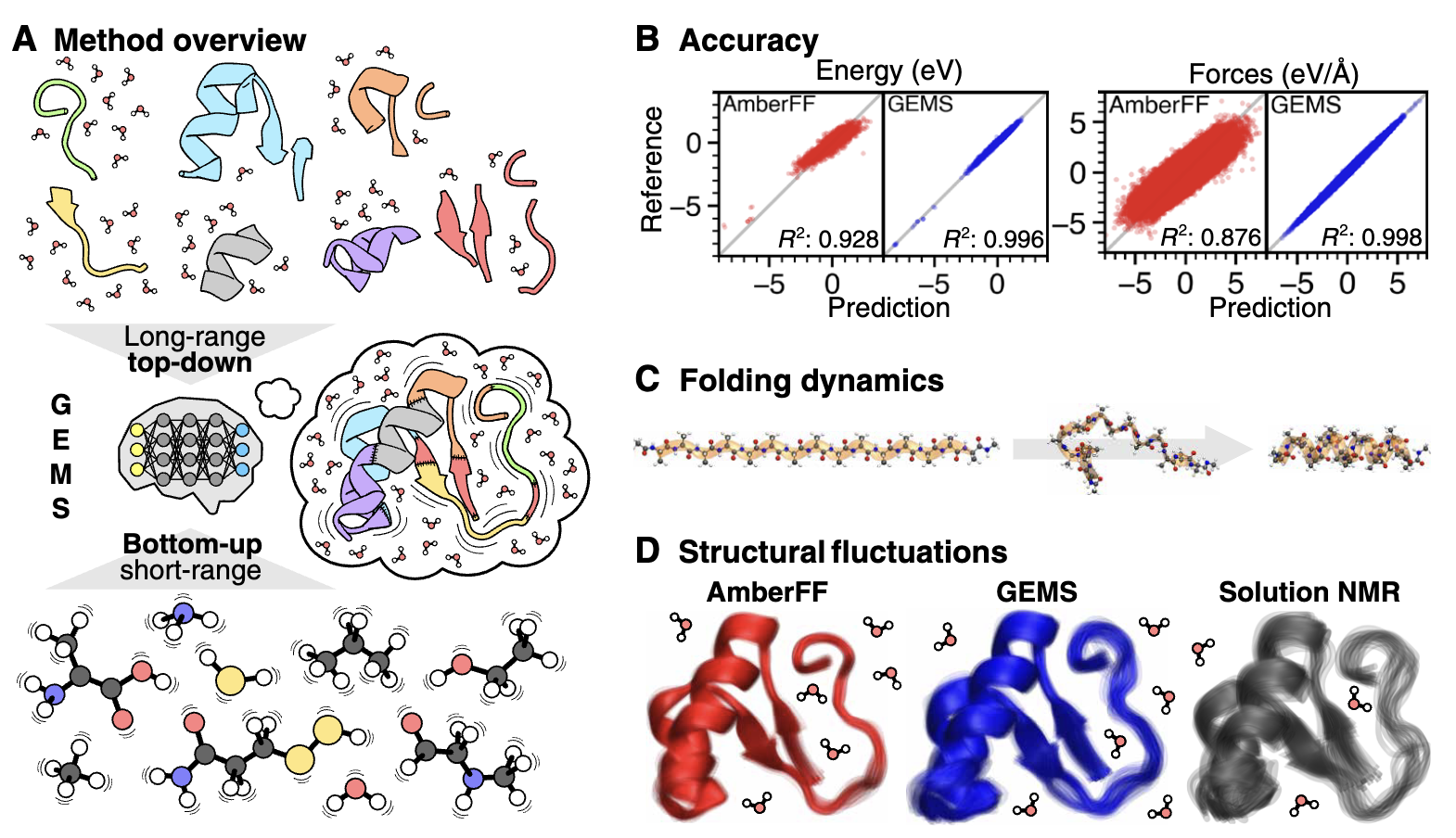
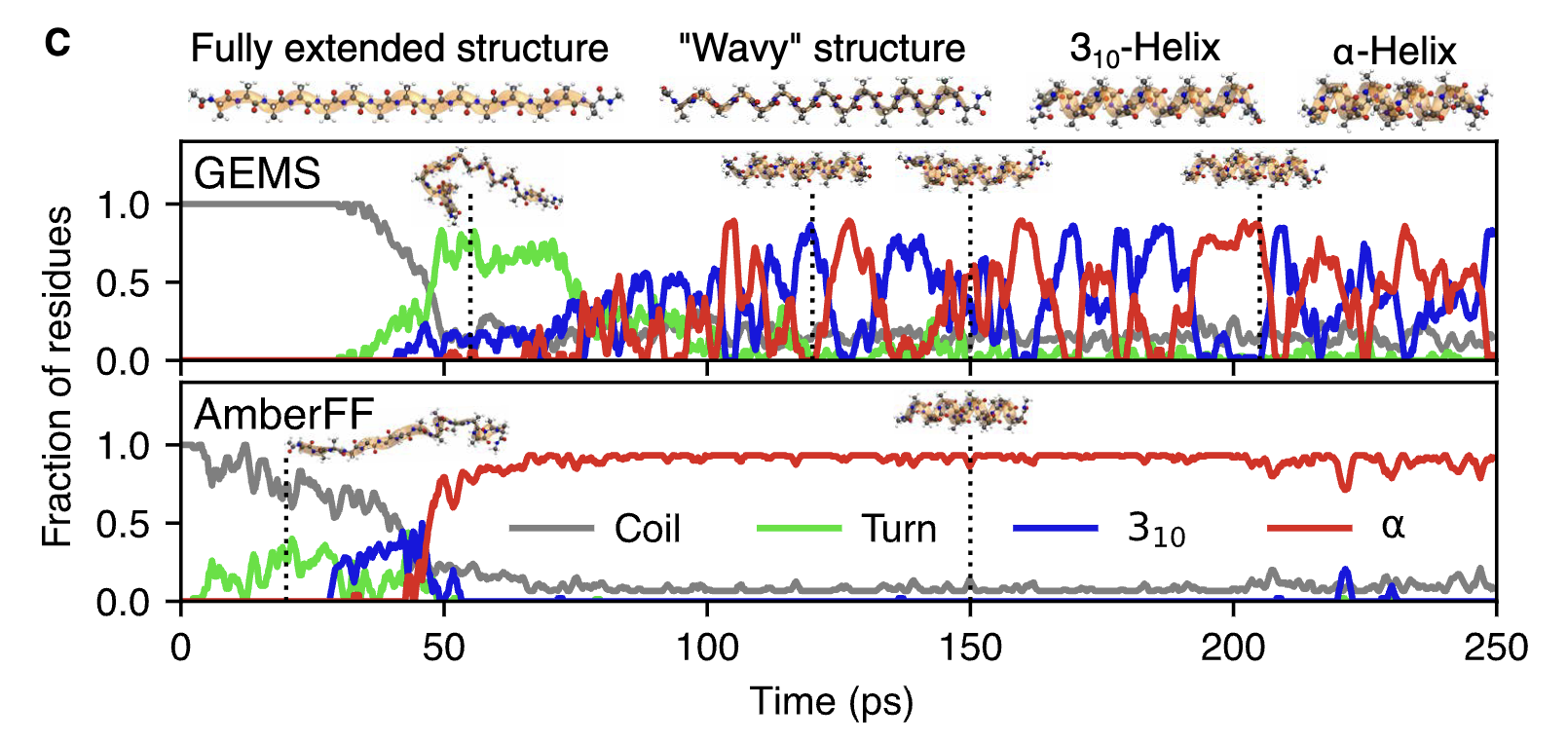
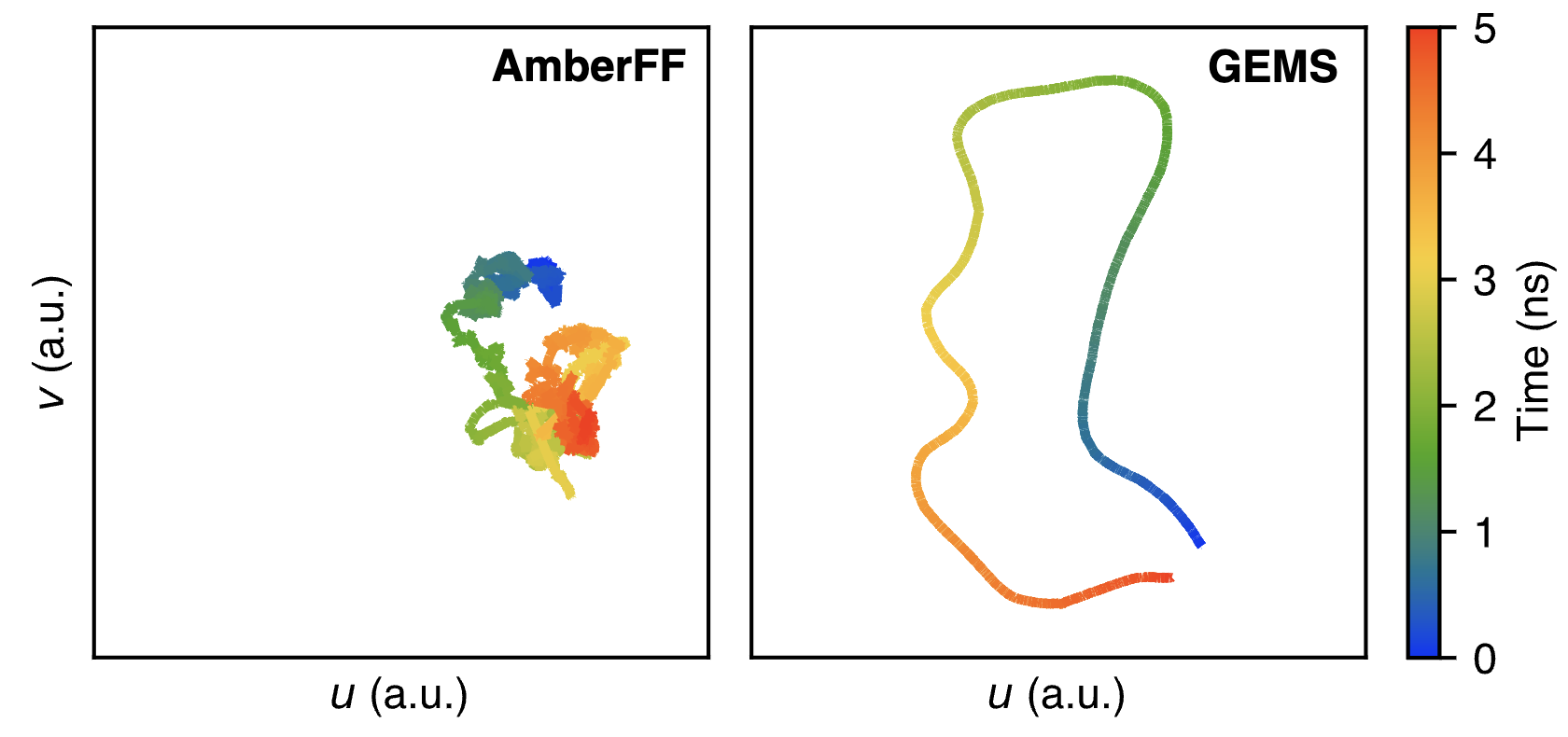
TORTOISE: Improving MD simulations seems to be quite tractable. There have been a few papers over the past 12 months that use neural network potentials for protein simulation—consider GEMS, or AI2BMD, or even the most recent MACE-OFF preprint. Scaling NNPs works well; why not just scale NNPs and use them to run MD simulations?
ACHILLES: For one, NNPs are ridiculously slow compared to normal MD—capturing protein conformational motion through MD is expensive enough without making it three orders of magnitude slower. You may be content with slow and accurate simulations, but I myself feel the need to go quickly. MD simulations will never be fast enough for high-throughput virtual screening. And how are we supposed to verify the alleged accuracy of these simulations, anyway?
TORTOISE: NMR measurements, perhaps, or terahertz spectroscopy. The ingenuity of experimentalists cannot be underestimated.
ACHILLES: I grant that this might work for a single protein. But you’ve managed to select methods that are even less scalable than growing crystals in a tray. This can’t be a general solution—it’s the age of “big data” now, not painstaking spectral analysis measured in graduate-student years.
TORTOISE: Ah, but we don’t need massive amounts of data for our benchmarks. NNPs and MD are physically motivated, so they’re much less prone to overfitting than the approaches you discuss. Generalization occurs naturally, without needing to resort to the sorts of paranoid dataset splits seen with sequence-only methods.
ACHILLES: Might this not simply arise from how small the models are today? Once an NNP must handle long-range forces, complex many-body interactions, and so on, these models will be just as susceptible to overfitting as co-folding methods. I know you like to hide in your shell from time to time, but robustness isn’t everything—if all you want is to prevent overfitting, you might as well go back to using AutoDock Vina.
TORTOISE: Not all approaches are equally susceptible to overfitting, and encoding proper inductive biases is one of the most important tasks of an ML researcher. The sorts of properties predicted by NNPs—forces, energy, charges, and so on—are intrinsically local and thus can be learned much more easily from a limited dataset. In fact, this is one of the strongest arguments for using a geometric GNN in the first place; we naturally account for the symmetries of the problem, as opposed to needing to learn them through vast datasets. Consider the analogies to Noether’s theorem.
ACHILLES: I must confess, I rarely revisit the 1910s.
TORTOISE: More fundamentally, learning energy as an intermediate variable is an incredibly fundamental task, and it’s unlikely that we can avoid some version of this task—particularly since diffusion models and AlphaFold are almost certainly both implicitly learning forcefields anyway.
Trying to one-shot the hardest problems in computational biochemistry and biophysics with “deep learning” will forever be hamstrung by memorization and overfitting, since the approach is fundamentally agnostic to the nature of the problem. I’m simply proposing that trying to learn physically motivated, verifiable, and practical models that correspond to our physical understanding of the world may be a more tractable strategy, even if it seems slower to you.
ACHILLES: You know that I respect your stepwise approach to scientific discovery, but I fear you’re confusing your own intrinsic conservatism for enlightenment. Haven’t you heard of Sutton’s “bitter lesson”? Encoding expert intuition always makes the researcher feel accomplished, and is often effective in the small-data regime, but never pays off in the end.
TORTOISE: Mr. Crab could say the same thing to you.
ACHILLES: Admittedly. But the task of the ML researcher is not dissimilar to that of the philosopher: to carve reality at its joints, as my kinsman Plato said, and find the natural partitions between concepts that make our tasks tractable. Choosing the right problem to tackle with deep learning might seem like encoding expert intuition in an un-Suttonian way, but really it’s a higher-order consideration, and one which itself still remains impervious to learning.
TORTOISE: And what, pray tell, makes your protein–ligand model a natural partition, and my NNPs an unnatural partition?
ACHILLES: The elegance of the protein–ligand task is that it corresponds to a real information bottleneck—all the complexity of the system can easily be distilled into a single number, and in practice the measurement is performed that way. In contrast, your model is only indirectly testable and verifiable.
TORTOISE: Only as indirectly as any other physics-based method is testable. Scientists have been doing this for some time, you know.
ACHILLES: And even more fundamentally, even a “physics-based model” is anything but. Scratch the surface of an NNP-powered MD simulation and you’ll see an ocean of questionable assumptions: band-gap collapse, nuclear quantum effects, spin–orbit coupling, quantum vs. classical zero-point energy, and so on and so forth. Even a model trained on full-configuration-interaction calculations won’t perfectly reflect reality. At the end of the day, you’ll have wasted ten million dollars on AWS computers generating gnostic simulated data that you could have spent getting real, tangible results without approximations.
TORTOISE: I’m willing to concede that at some scale, what you’re proposing might work. But you have no idea how much data you need to learn protein–ligand interactions. Have you done a scaling study; do you even have a back-of-the-envelope estimate for what your proposed model will cost? Who knows what the true dimensionality of protein–ligand interaction space is, or if it’s remotely learnable with the general architectures you propose? Someone’s going to have to generate all this data, and it’s not cheap—even fleet-footed Achilles can’t outrun the fundamental limitations of laboratory science.
ACHILLES: Ah, let’s not let our conversation fold back on itself. Isn’t it possible that there are latent low-dimensional representations of protein–ligand interactions that can make my structure-only training process more efficient?
TORTOISE: Possible, yes, but not guaranteed. To make matters worse, even if you train a protein–ligand model you’ll have to turn around and train another foundation model for protein–protein interactions, and another model for nucleotides, and another model for lipids, and so on and so forth.
ACHILLES: Presuming the first model succeeds, I would think this a fine outcome.
TORTOISE: We know what the scaling laws for NNPs are, and we know that they can scale across different domains of science even at sub-GPT1 parameter count. These are real advantages, and we ought to not be hasty in discarding them. Plus, it’s not like today’s methods are inconceivably far from where we want to go. Forcefield-based free-energy methods aren’t perfect, but they’re good enough to be useful. Doesn’t that suggest that we don’t need to get e.g. nuclear quantum effects exactly right to build a useful model?
ACHILLES: Scaling simulation across the chemical sciences is intriguing. You should tell Adam Marblestone; maybe you can build an FRO out of this idea. But we must stay focused on running the race at hand first and worry about the whole decathlon later. Perhaps we’ll be able to perform evolutionary model merging and pull out conformational ensembles at a later date, but I fear that your bias towards legacy simulation methods blinds you to the task at hand.
And arguing that FEP+ is good enough to be useful proves too much. Simply creating a histogram of distance by atom types is good enough to be useful; even plastic model kits are useful. Being useful at the small-data limit and being a viable path towards the future are very different, and I fear you confuse them at your own peril.
TORTOISE: Think strategically, my tactical friend. Let’s say we’re trying to get to the ultimate protein–ligand prediction model, which I’ll call the Galapagos Giant Model. If I train an NNP that’s halfway there, I’ve built something that’s immediately practically useful and which I can deploy to real problems. If you build a one-shot prediction model that’s halfway there, you’re going to get an overfit and confused model that takes a SMILES string and a sequence and returns meaningless noise.
ACHILLES: (Of course, first I’d have to train a model that was halfway to being halfway complete…)
TORTOISE: The ability of startups and research programs to bootstrap their way through increasing complexity is a critical determiner of their success—this is why YC tells companies to ship and start talking to users as soon as possible. We know that NNPs are already useful. How can you accomplish a similar feat with your approach?
ACHILLES: Ah, but your line of argumentation seems to rely on its own conclusion. Why is my hypothetical half-baked model unusable but yours is useful? Isn’t it just as possible that my model is useful across many domains but struggles to generalize to bizarre systems, while your model manages to be deeply useful nowhere?
The greatest advantage of simulation—its exactitude—is also its greatest weakness. A simulation-based workflow is only as strong as its weakest link, or what one might call its Achilles heel.
TORTOISE: Science aside, I fear the self-reference here will soon become ponderous.
ACHILLES: This might explain why the data on using NNPs in FEP are pretty bleak with today’s models, even though these models are undeniably a big improvement over the predecessor forcefield methods. Furthermore, fine-tuning models to be better at specific tasks seems to make them less general.
TORTOISE: I caution you not to rush to dismiss my approach prematurely. True ML FEP has never been tried, since the timescales remain inaccessible. Ligand-only corrections neglect the most important part of the system, which is the protein–ligand interactions—and we know that protein conformational motion is poorly described by forcefields, potentially biasing the entire simulation in deleterious ways. So no, I cannot feign surprise that these results are underwhelming.
ACHILLES: Still, you can’t deny that even the “overfit” ML methods of today like DiffDock are practically useful—it’s not like most drug programs deal with first-in-class structural families. How well do you think AlphaFold 3 works for kinase inhibitors? I would be surprised if the performance is not excellent.
TORTOISE: The dimensionality of ligand space is much higher than that of protein space.
ACHILLES: True. But it’s possible that generalization is easier in ligand space. I’m growing hungry—how about we continue this discussion over brunch?
TORTOISE: A capital idea. Shall we leave now?
ACHILLES: You are welcome to, but I may sit and read for a bit longer. As you know, I have a considerable speed advantage over you, and keeping up with the literature takes more and more of my time.
TORTOISE: Best of luck. We’ll see who gets there first!
[Exit TORTOISE.]
Thanks to Abhishaike Mahajan, Navvye Anand, Tony Kulesa, Pat Walters, and Ari Wagen for helpful conversations on these topics. I've also taken inspiration from talks I heard by Tom Sercu (Evolutionary Scale) and Pranam Chatterjee (Duke). Any errors are mine alone.