In his fantastic essay “The Two Cultures,” C. P. Snow observed that there was (in 1950s England) a growing divide between the academic cultures of science and the humanities:
Literary intellectuals at one pole—at the other scientists, and as the most representative, the physical scientists. Between the two a gulf of mutual incomprehension—sometimes (particularly among the young) hostility and dislike, but most of all lack of understanding. They have a curious distorted image of each other. Their attitudes are so different that, even on the level of emotion, they can't find much common ground.
He reflects on the origins of this phenomenon, which he contends is new to the 20th century, and argues that it ought to be opposed:
This polarisation is sheer loss to us all. To us as people, and to our society. It is at the same time practical and intellectual and creative loss, and I repeat that it is false to imagine that those three considerations are clearly separable. But for a moment I want to concentrate on the intellectual loss.
Snow’s essay is wonderful: his portrait of a vanishing cultural intellectual unity should inspire us all, scientists and otherwise, to improve ourselves, and the elegiac prose reminds the reader that even the best cultural institutions are fragile and fleeting things.
I want to make an analogous—but much less powerful—observation about the two cultures present in atomistic simulation. I’ll call these the “QM tribe” and the “MD tribe” for convenience: crudely, “people who use Gaussian/ORCA/Psi4 for their research” and “people who use Schrodinger/AMBER/OpenMM/LAMMPS for their research,” respectively. Although this dichotomy is crude, I contend there are real differences between these two groups, and that their disunity hurts scientific progress.
The Nature of Energy Surfaces
The most fundamental disagreement between these two cultures is in how they think about energy surfaces, I think. Most QM-tribe people think in terms of optimizing to discrete critical points on the potential energy surface: one can perform some sort of gradient-informed optimization to a ground state, or follow negative eigenvalues to a transition state.
Implicit to this assumption is that there exist well-defined critical points on the PES, and that finding such critical points is meaningful and productive. Conformers exist, and many people now compute properties as Boltzmann-weighted averages over conformational ensembles, but this is usually done for 10–100 conformers, not thousands or millions. Entropy and solvation, if they’re considered at all, are viewed as corrections, not key factors: since QM is so frequently used to study high-barrier bond-breaking processes where enthalpic factors dominate, one can often get reasonable results with cartoonish treatments of entropy.
In contrast, MD-tribe scientists generally don’t think about transition states as specific configurations of atoms—rather, a transition state can emerge from some sort of simulation involving biased sampling, but it’s just a position along some abstract reaction coordinate, rather than a structure which can be visualized in CYLView. Any information gleaned is statistical, rather than concretely visual (e.g. “what is the mean number of hydrogen bonds to this oxygen near this transition state”).
Unlike the QM tribe, MD-tribe scientists generally cannot study bond-breaking processes, and so focus on conformational processes (protein folding, aggregation, nucleation, transport) where entropy and solvation are of critical importance: as such, free energy is almost always taken into consideration by MD-tribe scientists, and the underlying PES itself is rarely (to my knowledge) viewed as a worthy topic of study in and of itself.
Molecular Representations
This divide also affects how the two cultures view the task of molecular representation. QM-tribe scientists generally view a list of coordinates and atomic numbers as the most logical representation of a molecule (perhaps with charge and multiplicity information). To the QM tribe, a minimum on the PES represents a structure, and different minima naturally ought to have different representations. Bonding and bond order are not specified, because QM methods can figure that out without assistance (and it’s not uncommon for bonds to change in a QM simulation anyway).
In contrast, people in the MD tribe generally want a molecular representation that’s independent of conformation, since many different conformations will intrinsically be considered. (See Connor Coley’s presentation from a recent MolSSI workshop for a discussion of this.) Thus, it’s common to represent molecules through their topology, where connectivity and bond order are explicitly specified. This allows for some pretty wild simulations of species that would be reactive in a QM simulation, but also means that e.g. tautomers can be a massive problem in MD (ref), since protons can’t equilibrate freely.
For property prediction, an uneasy compromise can be reached wherein one takes a SMILES string, performs a conformational search, and then Boltzmann-averages properties over all different conformers, to return a set of values which are associated only with the SMILES string and not any individual conformation. (Matt Sigman does this, as does Bobby Paton for NMR prediction.) This is a lot of work, though.
“A Gulf Of Mutual Incomprehension”
These differences also become apparent when comparing the software packages that different tribes use. Take, for instance, the task of predicting partial charges for a given small molecule. A QM-tribe scientist would expect these charges to be a function of the geometry, whereas an MD-tribe scientist would want the results to be explicitly geometry-independent (e.g.) so that they can be used for subsequent MD simulations.
The assumptions implicit to these worldviews mean that it’s often quite difficult to go from QM-tribe software packages to MD-tribe software packages or vice versa. I’ve been stymied before by trying to get OpenMM and openforcefield to work on organic molecules for which I had a list of coordinates and not e.g. a SMILES string—although obviously coordinates will at some point be needed in the MD simulation, most workflows expect you to start from a topology and not an xyz file.
Similarly, it’s very difficult to get the graphics package NGLView to illustrate the process of bonds breaking and forming—NGLView is typically used for MD, and expects that the system’s topology will be defined at the start of the simulation and never changed. (There are kludgy workarounds, like defining a new object for every frame, but it’s nevertheless true that NGLView is not made for QM-tribe people.)
(I’m sure that MD-tribe people are very frustrated by QM software as well, but I don’t have as much experience going in this direction. In general, MD tooling seems quite a bit more advanced than QM-tribe tooling; most MD people I’ve talked to seem to interact with QM software as little as possible, and I can’t say I blame them.)
“A Curious Distorted Image of Each Other”
There are also cultural factors to consider here. The questions that QM-tribe scientists think about are different than those that MD-tribe scientists think about: a somewhat famous QM expert once told me that they were “stuck on an ivory tower where people hold their nose when it comes to DFT, forget anything more approximate,” whereas MD-tribe scientists often seem alarmingly unconcerned about forcefield error but are obsessed with proper sampling and simulation convergence.
It seems that most people have only a vague sense of what their congeners in the other tribe actually work on. I don’t think most QM-tribe scientists I know have ever run or analyzed a regular molecular dynamics simulation using e.g. AMBER or OpenMM, nor do I expect that most MD-tribe scientists have tried to find a transition state in Gaussian or ORCA. In theory, coursework could remedy this, but education for QM alone already seems chaotic and ad hoc—trying to cram in MD, statistical mechanics, etc is probably ill-advised at the present.
Social considerations also play a role. There’s limited crosstalk between the two fields, especially at the trainee level. How many QM people even know who Prayush Tiwary is, or Michael Shirts, or Jay Ponder? How many MD graduate students have heard of Frank Neese or Troy Van Voorhis? As always, generational talent manages to transcend narrow boundaries—but rank-and-file scientists would benefit immensely from increased contact with the other tribe.
“Unite Them”
I’m not an expert on the history of chemistry, but my understanding is that the two fields were not always so different: Martin Karplus, Arieh Warshel, and Bill Jorgensen, key figures in the development of modern MD, were also formidable quantum chemists. (If any famous chemists who read this blog care to share their thoughts on this history, please email me: you know who you are!)
And as the two fields advance, I think they will come closer together once more. As QM becomes capable of tackling larger and larger systems, QM-tribe scientists will be forced to deal with more and more complicated conformational landscapes: modern enantioselective catalysts routinely have hundreds of ground-state complexes to consider (ref), and QSimulate and Amgen recently reported full DFT calculations on protein–ligand complexes (ref).
Similarly, the increase in computing power means that many MD use cases (like FEP) are now limited not by insufficient sampling but by the poor energetics of the forcefields they employ. This is difficult to prove unequivocally, but I’ve heard this in interviews with industry folks, and there are certainly plenty of references complaining about poor forcefield accuracy (1, 2): a Psivant review dryly notes that “historically solvation energy errors on the order of 2–3 kcal/mol have been considered to be accurate,” which is hardly encouraging.
Many QM-tribe professors now work on dynamics: Dean Tantillo and Todd Martinez (who have long been voices “crying out in the wilderness” for dynamics) perhaps most prominently, but also Steven Lopez, Daniel Ess, Fernanda Duarte, Peng Liu, etc. And MD-tribe professors seem more and more interested in using ML mimics of QM to replace forcefields (e.g.), which will inevitably lead them down the speed–accuracy rabbit hole that is quantum chemistry. So it seems likely to me that the two fields will increasingly reunite, and that being a good 21st-century computational chemist will require competency in both areas.
If this is true, the conclusions for individual computational chemists are obvious: learn techniques outside your specialty, before you get forcibly dragged along by the current of scientific progress! There’s plenty to learn from the other culture of people that deals with more-or-less the same scientific problems you do, and no reason to wait.
As a denizen of quantum chemistry myself, I apologize for any misrepresentations or harmful stereotypes about practitioners of molecular dynamics, for whom I have only love and respect. I would be happy to hear any corrections over email.
An important problem with simulating chemical reactions is that reactions generally take place in solvent, but most simulations are run without solvent molecules. This is a big deal, since much of the inaccuracy associated with simulation actually stems from poor treatment of solvation: when gas phase experimental data is compared to computations, the results are often quite good.
Why don’t computational chemists include solvent molecules in their models? It takes a lot of solvent molecules to accurately mimic bulk solvent (enough to cover the system with a few different layers, usually ~103).1 Since most quantum chemical methods scale in practice as O(N2)–O(N3), adding hundreds of additional atoms has a catastrophic effect on the speed of the simulation.
To make matters worse, the additional degrees of freedom introduced by the solvent molecules are very “flat”—solvent molecules don’t usually have well-defined positions about the substrate, meaning that the number of energetically accessible conformations goes to infinity (with attendant consequences for entropy). This necessitates a fundamental change in how calculations are performed: instead of finding well-defined extrema on the electronic potential energy surface (ground states or transition states), molecular dynamics (MD) or Monte Carlo simulations must be used to sample from an underlying distribution of structures and reconstruct the free energy surface. Sufficient sampling usually requires consideration of 104–106 individual structures,2 meaning that each individual computation must be very fast (which is challenging for quantum chemical methods).
The title of this paper makes me so sad, because these techniques are still ignored by most organic chemists.
Given the complexity this introduces, it’s not surprising that most computational organic chemists try to avoid explicit solvent at all costs. The typical workaround is to use “implicit solvent” models, which “reduce the complexity of individual solvent−solute interactions such as hydrogen-bond, dipole−dipole, and van der Waals interactions into a fictitious surface potential... scaled to reproduce the experimental solvation free energies” (Baik). This preserves the well-defined potential energy surfaces that organic chemists are accustomed to, so you can still find transition states by eigenvector following, etc.
Implicit solvent models like PCM, COSMO, or SMD are better than nothing, but are known to struggle for charged species. In particular, they don’t really describe explicit inner-sphere solvent–solute interactions (like hydrogen bonding), meaning that they’ll behave poorly when these interactions are important. Dan Singleton’s paper on the Baylis–Hillman reaction is a nice case study of how badly implicit solvent can fail: even high-level quantum chemical methods are useless when solvation free energies are 10 kcal/mol off from experiment!
An even more important but still open issue is solvation. In the opinion of the authors it is a ‘scandal’ that in 2018 no routine free energy solvation method is available beyond (moderately successful) continuum theories such as COSMO-RS and SMD and classical FF/MD-based explicit treatments.
When computational studies have been performed in explicit solvent, the results have often been promising: Singleton has studied diene hydrochlorination and nitration of toluene, and Peng Liu has recently conducted a nice study of chemical glycosylation. Nevertheless, these studies all require heroic levels of effort: quantum chemistry is still very slow, and so a single free energy surface might take months and months to compute.3
One promising workaround is using machine learning to accelerate quantum chemistry. Since these MD-type studies look at the same exact system over and over again, we could imagine first training some sort of ML model based on high-level quantum chemistry data, and then employing this model over and over again for the actual MD run. As long as (1) the ML model is faster than the QM method used to train it and (2) it takes less data to train the ML model than it would to run the simulation, this will save time: in most cases, a lot of time.
(This is a somewhat different use case than e.g. ANI-type models, which aim to achieve decent accuracy for any organic molecule. Here, we already know what system we want to study, and we’re willing to do some training up front.)
A lot of people are working in this field right now, but today I want to highlight some work that I liked from Fernanda Duarte and co-workers. Last year, they published a paper comparing a few different ML methods for studying quasiclassical dynamics (in the gas phase), and found that atomic cluster expansion (ACE) performed better than Gaussian approximation potentials while training faster than NequIP. They then went on to show that ACE models could be trained automatically through active learning, and used the models to successfully predict product ratios for cycloadditions with post-TS bifurcations.
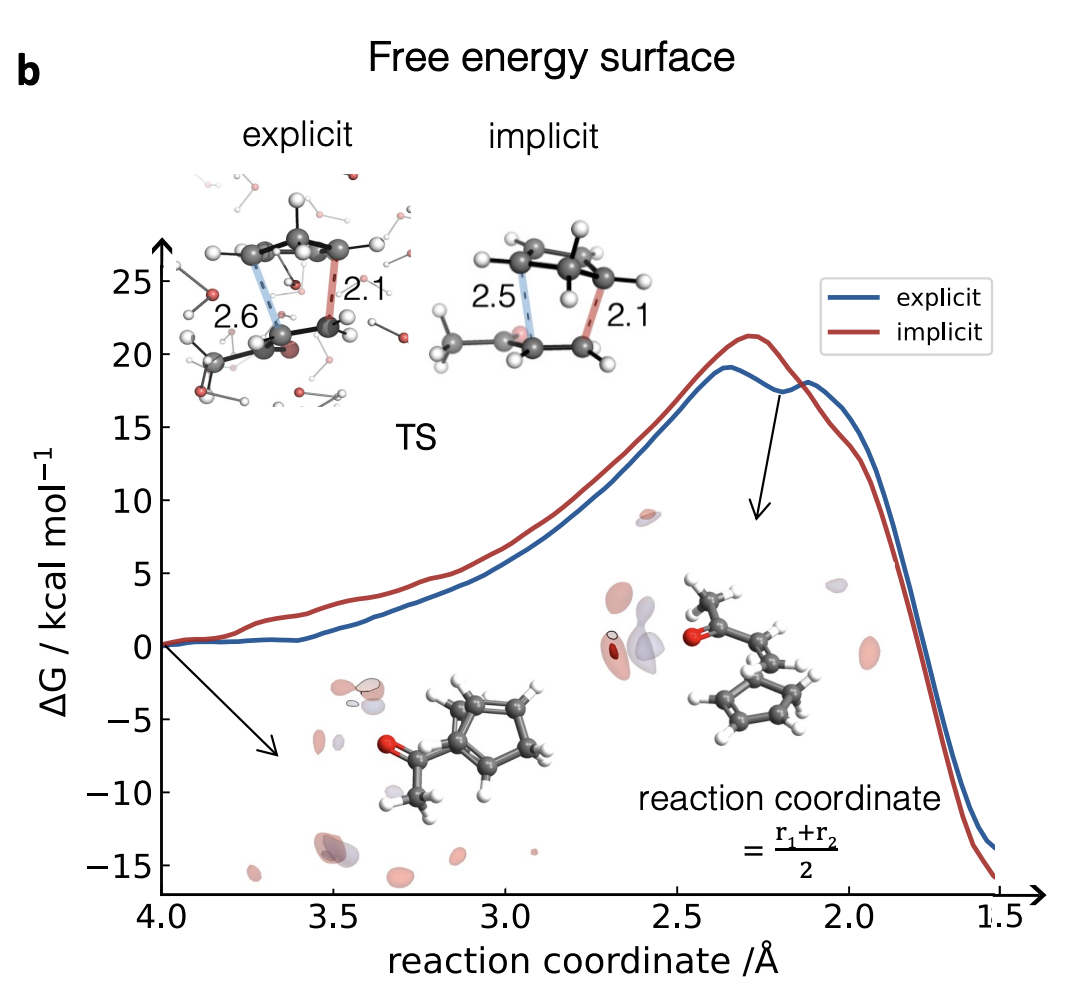
Their new paper, posted on ChemRxiv yesterday, applies the same ACE/active learning approach to studying reactions in explicit solvent, with the reaction of cyclopentadiene and methyl vinyl ketone chosen as a model system. This is more challenging than their previous work, because the ML model now not only has to recapitulate the solute reactivity but also the solute–solvent and solvent–solvent interactions. To try and capture all the different interactions efficiently, the authors ended up using four different sets of training data: substrates only, substrates with 2 solvent molecules, substrates with 33 solvent molecules, and clusters of solvent only.
Previously, the authors used an energy-based selector to determine if a structure should be added to the training set: they predicted the energy with the model, ran a QM calculation, and selected the structure if the difference between the two values was big enough. This approach makes a lot of sense, but has the unfortunate downside that a lot of QM calculations are needed, which is exactly what this ML-based approach is trying to avoid. Here, the authors found that they could use similarity-based descriptors to select data points to add to the training set: these descriptors are both more efficient (needing fewer structures to converge) and faster to compute, making them overall a much better choice. (This approach is reminiscent of the metadynamics-based approach previously reported by John Parkhill and co-workers.)
With a properly trained model in hand, the authors went on to study the reaction with biased sampling MD. They find that the reaction is indeed accelerated in explicit water, and that the free energy surface begins to look stepwise, as opposed to the concerted mechanism predicted in implicit solvent. (Singleton has observed similar behavior before, and I’ve seen this too.) They do some other interesting studies: they look at the difference between methanol and water as solvents, argue that Houk is wrong about the role of water in the TS,4 and suggest that the hydrophobic effect drives solvent-induced rate acceleration.5
Figure 4B from the paper, showing the change in the PES.
The results they find for this particular system are interesting, but more exciting is the promise that these techniques may soon become accessible to “regular” computational chemists. Duarte and co-workers have shown that ML can be used to solve an age-old problem in chemical simulation; if explicit solvent ML/MD simulations of organic reactions become easy enough for non-experts to run, I have no doubt that they will become a valued and essential part of the physical organic chemistry toolbox. Much work is needed to get to that point—new software packages, further validation on new systems, new ways to assess quality and check robustness of simulations, and much more—but the vision behind this paper is powerful, and I can’t wait until it comes to fruition.
Thanks to Croix Laconsay for reading a draft of this post.
Footnotes
This video from Chris Cramer makes the point nicely.
This obviously depends on the system in question, and what processes are being studied. But in general insufficient sampling is a big issue in molecular dynamics, which I think is underappreciated by organic chemists wading into the area. Jeff Grossman has a nice paper on this.
If you look carefully, many people who claim to be doing big ab initio molecular dynamics studies are actually doing semiempirical molecular dynamics. This isn’t dishonest per se, but it’s a little underwhelming to a computational chemist, especially when it’s only mentioned in the SI. Things get even more confusing when plane wave DFT is employed: in theory, plane wave DFT can be just as accurate as regular DFT, but in practice there are some sneaky approximations that often get introduced.
This argument hinges on whether uphill dynamics (starting from reactants, going to transition state) or downhill dynamics (starting from transition state, going to reactants) are more appropriate. The authors argue that "uphill dynamics allow the solvent sufficient time to reorganise [sic] before the trajectory passes the free energy barrier, providing a more realistic view of solvent behaviour [sic] during the reaction." I'm not fully convinced by this—isn't the idea that the system reorganizes to minimize the energy of the transition state a basic precept of transition state theory? But I'm not convinced I understand these issues deeply enough to have an opinion; I will leave this to the experts.
This argument hearkens back to some old-school computational organic chemistry I love from Bill Jorgensen, studying the hydrophobic effect on conformational preferences of butane. We usually think of the hydrophobic effect as associated with macromolecules (ligands binding to proteins, etc), but it can still matter in tiny systems!
Today, most research is done by academic labs funded mainly by the government. Many articles have been written on the shortcomings with academic research: Sam Rodriques recently had a nice post about how academia is ultimately an educational institution, and how this limits the quality of academic research. (It’s worth a read; I’ve written about these issues from a fewangles, and will probably write more at a later date.)
The major alternative to academic research that people put forward is focused research organizations (FROs): large, non-profit research organizations capable of tackling big unsolved problems. These organizations, similar in scope and ambition to e.g. CERN or LIGO, are envisioned to operate with a budget of $20–100M over five years, making them substantially larger and more expensive than a single academic lab. This model is still being tested, but it seems likely that some version of FROs will prove effective for appropriately sized problems.
But FROs have some disadvantages, too: they represent a significant investment on the part of funders, and so it’s important to choose projects where there’s a high likelihood of impact in the given area. (In contrast, it’s expected that most new academic labs will focus on high-risk projects, and pivot if things don’t work out in a few years.) In this piece, I propose a new form of scientific organization that combines aspects of both FROs and academic labs: for-profit micro focused research organizations (FPµFROs).
The key insight behind FPµFROs is that existing financial markets could be used to fund scientific research when there is a realistic possibility for profit as a result of the research. This means that FPµFROs need not be funded by the government or philanthropic spending, but could instead raise capital from e.g. venture capitalists or angel investors, who have access to substantially more money and are used to making high-risk, high-reward investments.
FPµFROs would also be smaller and more nimble than full-fledged FROs, able to tackle high-risk problems just like academia. But unlike academic labs, FPµFROs would be able to spend more freely and hire more aggressively, thus circumventing the human capital issues that plague academic research. While most academic labs are staffed entirely with inexperienced trainees (as Rodriques notes above), FPµFROs could hire experienced scientists, engineers, and programmers, thus accelerating the rate of scientific progress.
One limitation of the FPµFRO model is that research would need to be profitable within a reasonable time frame. But this limitation might actually be a blessing in disguise: the need for profitability means that FPµFROs would be incentivized to provide real value to firms, thus preventing useless research through the magic of Adam Smith’s invisible hand.
Another disadvantage of FPµFROs is that they must be able to achieve success with relatively little funding (probably around $10M; big for academia, but small compared to a FRO). This means that their projects would have to be modest in scope. I think this is probably a blessing in disguise, though. Consider the following advice from Paul Graham:
Empirically, the way to do really big things seems to be to start with deceptively small things.… Maybe it's a bad idea to have really big ambitions initially, because the bigger your ambition, the longer it's going to take, and the further you project into the future, the more likely you'll get it wrong.
Thus, the need for FPµFROs to focus on getting a single “minimal viable product” right might be very helpful, and could even lead to more impactful firms later on.
In conclusion, FPµFROs could combine the best qualities of academic labs and FROs: they would be agile and risk-tolerant, like academic labs, but properly incentivized to produce useful research instead of publishing papers, like FROs. This novel model should be investigated further as a mechanism for generating new scientific discoveries at scale with immediate short-term utility.
* * *
Hopefully it’s clear by now that this is a joke: an FPµFRO is just a startup.
The point of this piece isn’t to criticize FROs or academia: both have their unique advantages relative to startups, and much has been written about the relative advantages and disadvantages of different sorts of research institutions (e.g.).
Rather, I want to remind people that startups can do really good scientific work, something that many people seem to forget. It’s true that basic research can be a public good, and something that’s difficult to monetize within a reasonable timeframe. But most research today isn’t quite this basic, which leads me to suspect that many activities today confined to academic labs could be profitably conducted in startups.
Academics are generally very skeptical of organizations motivated by profit. But all incentives are imperfect, and the drive to achieve profitability pushes companies to provide value to real customers, which is more than many academics motivated by publication or prestige ever manage to achieve. It seems likely that for organizations focused on applied research, profit is the least bad incentive.
I’ll close with a quote from Eric Gilliam’s recent essay on a new model for “deep tech” startups:
Our corporate R&D labs in most industries have taken a step back in how “basic” their research is. Meanwhile, what universities call ‘applied’ research has become much less applied than it used to be. This ‘middle’ of the deep tech pipeline has been hollowed out.
What Eric proposes in his piece, and what I’m arguing here, is that scientific startups can help fill this void: not by replacing FROs and academic research, but by complementing them.
Thanks to Ari Wagen for reading a draft of this piece.
The concept of pKa is introduced so early in the organic chemistry curriculum that it’s easy to overlook what a remarkable idea it is.
Briefly, for the non-chemists reading this: pKa is defined as the negative base-10 logarithm of the acidity constant of a given acid H–A:
pKa := -log10([HA]/[A-][H+])
Unlike pH, which describes the acidity of a bulk solution, pKa describes the intrinsic proclivity of a molecule to shed a proton—a given molecule in a given solvent will always have the same pKa, no matter the pH. This makes pKa a very useful tool for ranking molecules by their acidity (e.g. the Evans pKa table).
The claim implicit in the definition of pKa is that a single parameter suffices to describe the acidity of each molecule.1 In general, this isn’t true in chemistry—there’s no single “reactivity” parameter which describes how reactive a given molecule is. For various regions of chemical space a two-parameter model can work, but in general we don’t expect to be able to evaluate the efficacy of a given reaction by looking up the reactivity values of the reactants and seeing if they’re close enough.
Instead, structure and reactivity interact with each other in complex, high-dimensional ways. A diene will react with an electron-poor alkene and not an alcohol, while acetyl chloride doesn’t react with alkenes but will readily acetylate alcohols, and a free radical might ignore both the alkene and the alcohol and abstract a hydrogen from somewhere else. Making sense of this confusing morass of different behaviors is, on some level, what organic chemistry is all about. The fact that the reactivity of different functional groups depends on reaction conditions is key to most forms of synthesis!
But pKa isn’t so complicated. If I want to know whether acetic acid will protonate pyridine in a given solvent, all I have to do is look up the pKa values for acetic acid and pyridinium (pyridine’s conjugate acid). If pyridinium has a higher pKa, protonation will be favored; otherwise, it’ll be disfavored. More generally, one can predict the equilibrium distribution of protons amongst N different sites from a list of the corresponding pKas.
Why is pKa so well-behaved? The key assumption underlying the above definition is that ions are free and do not interact with one another. This allows us to neglect any specific ion–ion interactions, and makes the scale universal: if the pyridinium cation and the acetate anion never interact, then I can learn everything I need to about pyridinium acetate just by measuring the pKas of pyridine and acetic acid in isolation.
This assumption is quite good in solvents like water or DMSO, which excel at stabilizing charged species, but progressively breaks down as one travels to the realm of nonpolar solvents. As ions start to pair with themselves, specific molecule–molecule interactions become important. The relative size of the anions can matter: in a nonpolar solvent, a small anion will be better stabilized by a small cation than by a large, diffuse cation, meaning that e.g. acetate will appear more acidic when protonating smaller molecules. Other more quotidian intermolecular interactions, like hydrogen bonding and π-stacking, can also play a role.
And the ions aren’t the only thing that can stick together: aggregation of acids is often observed in nonpolar solvents. Benzenesulfonic acid forms a trimer in benzonitrile solution, which is still pretty polar, and alcohols and carboxylic acids are known to aggregate under a variety of conditions as well.2 Even seemingly innocuous species like tetrabutylammonium chloride will aggregate at high concentrations (ref, ref).
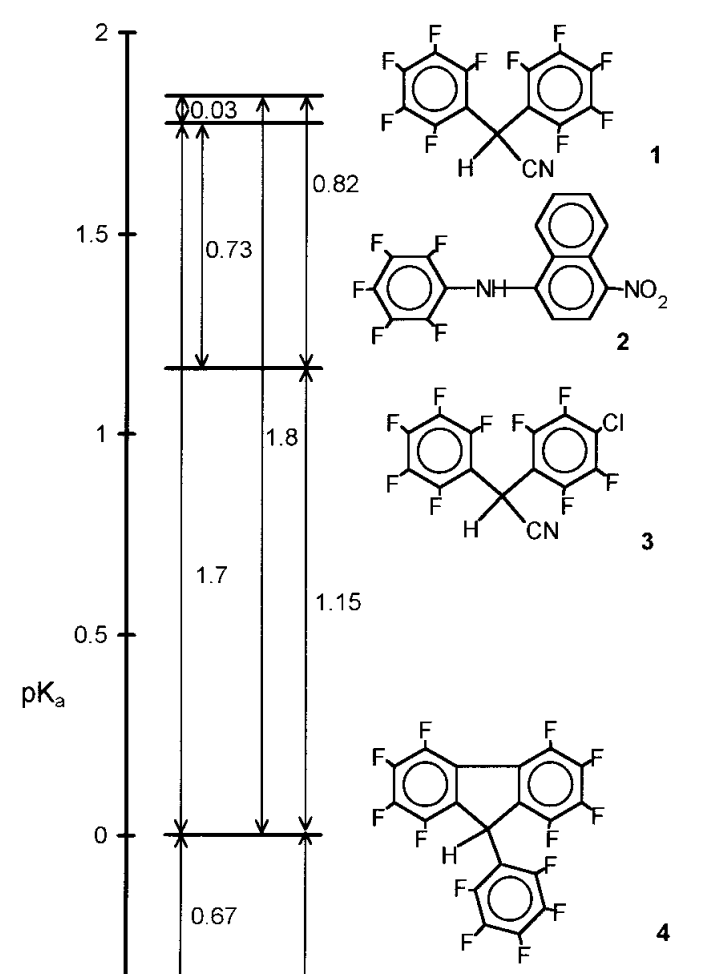
To reliably extend pKa scales to nonpolar solvents, one must thus deliberately choose compounds which resist aggregation. As the dielectric constant drops, so does the number of such compounds. The clearest demonstration of this I’ve found is a series of papers (1, 2) by pKa guru Ivo Leito measuring the acidity of a series of fluorinated compounds in heptane:
A portion of the scale, showing the compounds employed.
This effort, while heroic, demonstrates the futility of measuring pKa in nonpolar media from the standpoint of the synthetic chemist. If only weird fluoroalkanes engineered not to aggregate can have pKa values, then the scale may be analytically robust, but it’s hardly useful for designing reactions!
The key point here is that the difficulty of measuring pKa in nonpolar media is not an analytical barrier which can be surmounted by new and improved technologies, but rather a fundamental breakdown in the idea of pKa itself. Even the best pKa measurement tool in the world can’t determine the pKa of HCl in hexanes, because no such value exists—the concept itself is borderline nonsensical. Chloride will ion-pair with everything in hexanes, hydrogen chloride will aggregate with itself, chloride will stick to hydrogen chloride, and so forth. Asking for a pKa in this context just doesn't make much sense.3
It’s important to remember, however, that just because the pKa scale no longer functions in nonpolar solvents doesn’t mean that acids don’t have different acidities. Triflic acid in toluene will still protonate just about everything, whereas acetic acid will not. Instead, chemists wishing to think about acidity in nonpolar media have to accept that no one-dimensional scale will be forthcoming. The idealized world of pKa we’re accustomed to may no longer function in nonpolar solvents, but chemistry itself still works just fine.
Thanks to Ivo Leito for discussing these topics with me over Zoom, and to Joe Gair for reading a draft of this post.
Footnotes
Really, each proton.
Ivo Leito called carboxylic acids "the world champions of aggregation" when I asked him about these issues.
Even experimentally nonsensical pKas can be simulated, though: Jorgensen famously used free energy perturbation to compute the pKa of ethane in water.
You are a scientist, not a lab monkey. You ought not to view your degree as “six years of hard labor in the chemistry mines.” Always make time to go to interesting seminars, talk with other people about their research, and read the literature. Otherwise, what’s the point of being a scientist?
Only one person is really looking out for your best interests: you. Your advisor, your classmates, and your collaborators all have their own distinct incentives and interests, which will often roughly align with yours, but will never align perfectly.
Your research interests will also not match up perfectly with those of your advisor. Your job as a graduate student is to find the intersection between what the two of you care about, and work there. Otherwise, one of you will be unhappy.
The more non-chemists in your life, the better your mental health will be. (h/t Arthur Brooks)
Try to maximize the ratio of “thinking”/publishable work to mindless SI work. Any project will take some grinding, but the thinking work is (ideally) what you’ve been recruited for, what you’ll present on, and what’ll get you a job. If your advisor views you only as a set of hands… be very worried.
Cold emails to scientists work much better than it seems they ought to. Most professors spend their entire career trying to get people to care about their work—if you’re interested, they’ll usually talk your ear off.
Read your PI’s old papers, as many as possible. Too often students are totally ignorant of the work that occurred a decade before they joined the lab, and end up repeating it or falling into the same pitfalls time and time again.
Learn to code; please stop performing curve fits in Excel. (cf. pmarca)
Be outcome focused. Each day, ask yourself “What is the biggest problem I’m facing in my research?” If whatever you’re doing isn’t addressing that problem, you’re wasting your time. Sometimes this means stopping all experiments and reading papers for a few weeks; sometimes this looks like running reactions; sometimes this looks like just sitting at your desk and writing. (h/t Brian Liau for giving me this advice when I started graduate school)
Be outcome focused on the big scale, too. Figure out what success in graduate school looks like—what your ideal job is, and what it takes to get that sort of job—and then pursue those outcomes relentlessly. Perhaps in an ideal world we could all follow our natural curiosity to our heart’s content, but that’s not real life, not in science as I’ve known it.
Success in graduate school may be necessary for your life goals, but it won’t be sufficient. At the end of the day, science is just a job, and your molecules will never love you. So don’t work so hard that you put the rest of your life on hold; don’t make science the highest good in your worldview. (cf. Augustine)
Thanks to Joe Gair for reading a draft of this piece.