When thinking about science, I find it helpful to divide computations into two categories: models and oracles.
In this dichotomy, models are calculations which act like classic ball-and-stick molecular models. They illustrate that something is geometrically possible—that the atoms can literally be arranged in the proper orientation—but not much more. No alternative hypotheses have been ruled out, and no unexpected insights have emerged. A model has no intelligence of its own, and only reflects the thought that the user puts into it.
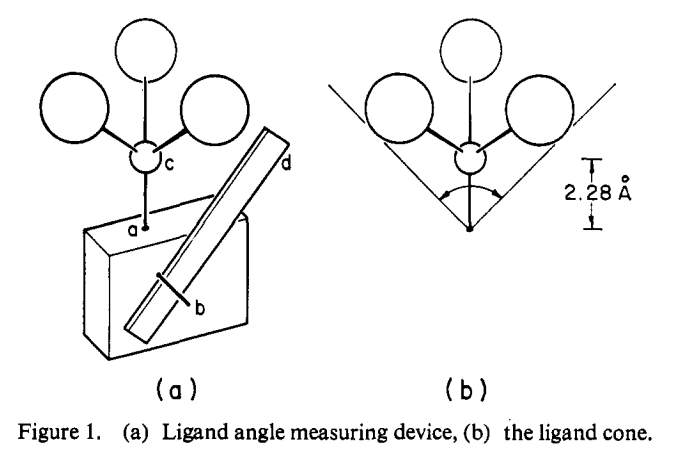
This isn’t bad! Perhaps the most striking example of the utility of models is Tolman’s original cone angle report, where he literally made a wooden model of different phosphine ligands and measured the cone angle with a ruler. The results are excellent!
Figure 1, from Tolman’s paper.
In contrast, an oracle bestows new insights or ideas upon a petitioner—think the Oracle at Delphi. This is what a lot of people imagine when they think of computation: we want the computer to predict totally unprecedented catalysts, or figure out the mechanism without any human input. We bring our problems to the superintelligence, and it solves them for us.
The Oracle, by Camille Miola (1880). Picture from Wikimedia Commons.
In reality, every simulation is somewhere between these two limiting extremes. No matter how hard you try, a properly executed DFT calculation will not predict formation of a methyl cation to be a low-barrier process—the computational method used understands enough chemistry to rule this out, even if the user does not. On the flip side, even the most sophisticated calculations all involve some form of human insight or intuition, either explicitly or implicitly. We’re still very far away from the point where we can ask the computer to generate the structures of new catalysts (or medicines) and expect reasonable, trustworthy results. But that’s ok; there’s a lot to be gained from lesser calculations! There’s no shame in generating computational models instead of oracles.
What’s crucial, though, is to make sure that everyone—practitioners, experimentalists, and readers—understands where a given calculation falls on the model–oracle continuum. An expert might understand that a semiempirical AIMD study of reaction dynamics is likely to be only qualitatively correct (if that), but does the casual reader? I’ve talked to an unfortunate number of experimental chemists who think a single DFT picture means that we can “predict better catalysts,” as if that were a button in GaussView. The appeal of oracles is seductive, and we have to be clear when we’re presenting models instead. (This ties into my piece about computational nihilism.)
Finally, this piece would be incomplete if I didn’t highlight Jan Jensen and co-workers’ recent work on automated design of catalysts for the Morita–Baylis–Hillman reaction. The authors use a generative model to discover tertiary amines with lower DFT-computed barriers than DABCO (the usual catalyst), and then experimentally validate one of their candidates, finding that it is indeed almost an order-of-magnitude faster than DABCO. It’s difficult to underscore how groundbreaking this result is; as the authors dryly note, “We believe this is the first experimentally verified de novo discovery of an efficient catalyst using a generative model.” On the spectrum discussed above, this is getting pretty close to “oracle.”
Figure 3 from the paper, illustrating discovery of new catalysts.
Nevertheless, the choice of model system illustrates how far the field still has to go. The MBH reaction is among the best-studied reactions in organic chemistry, as illustrated by Singleton’s 2015 mechanistic tour de force (and references therein, and subsequent work), so Jensen and co-workers could have good confidence that the transition state they were studying was correct and relevant. Furthermore, as I understand it, the MBH reaction can be catalyzed by just about any tertiary amine—there aren’t the sort of harsh activity cliffs or arcane structural requirements that characterize many other catalytic reactions. Without either of these factors—well-studied mechanism or friendly catalyst SAR—I doubt this work would be possible.
This point might seem discouraging, but I mean it in quite the opposite way. De novo catalyst design isn’t impossible for mysterious and opaque reasons, but for quite intelligible reasons—mechanisms are complicated, catalysts are hard to design, and we just don’t understand enough about what we’re doing, experimentally or computationally. What Jensen has shown us is that, if we can address these issues, we can expect to start converging on oracular results. I find this very exciting!
Jan Jensen was kind enough to reply to this post on Twitter with a few thoughts and clarifications, which are worth reading.
In science, if you know what you are doing, you should not be doing it. In engineering, if you do not know what you are doing, you should not be doing it.
—Richard Hamming
What’s the difference between science and engineering?
Five years ago, I would have said something along the lines of “engineers study known unknowns, scientists study unknown unknowns” (with apologies to Donald Rumsfeld), or made a distinction between expanding the frontiers of knowledge (science) and settling already-explored territory (engineering).
These thoughts seem broadly consistent with what others think. Boston University’s College of Engineering says:
Engineers are not a sub-category of scientists. So often the two terms are used interchangeably, but they are separate, albeit related, disciplines. Scientists explore the natural world and show us how and why it is as it is. Discovery is the essence of science. Engineers innovate solutions to real-world challenges in society. While it is true that engineering without science could be haphazard; without engineering, scientific discovery would be a merely an academic pursuit.
Science is knowledge based on observed facts and tested truths arranged in an orderly system that can be validated and communicated to other people. Engineering is the creative application of scientific principles used to plan, build, direct, guide, manage, or work on systems to maintain and improve our daily lives.
As I’ve started thinking more about the structure of the modern research system, and what its proper scope and purpose should be, I’ve grown increasingly skeptical of these distinctions. The claim I want to make in this post is that, following the above definitions of engineering, most chemistry is engineering. I don’t think this is bad! In fact, I think that many chemists could benefit from borrowing from an engineering mindset, and should consider incorporating this perspective in their self-conception.
Much of Organic Chemistry is Engineering
I want to return to the BU and NSPE definitions, because I think they’re concise and well-written, and take as gospel that scientists “explore the natural world and show us how and why it is as it is,” while engineers “innovate solutions to real-world challenges in society” (we’ll revisit issues of definition later). In short, developing something you want other people to use makes you an engineer. Which branches of modern organic chemistry are science, and which are engineering?
Method development—one of my core interests—seems like a good candidate for “engineering.” Researchers in this space identify unsolved problems in organic synthesis, develop methods or catalysts to solve these problems, and then (in many cases) advertise, license, & sell their solutions to consumers! (If you don’t believe me, just look at the “Organic Synthesis” tab of the Sigma-Aldrich Professor Product Portal.) If these products weren’t molecules and were instead mechanical gadgets, nothing about this would be obviously scientific.
And the problems chosen are identified almost purely on the basis of what might be useful to potential users. There’s no clearer illustration of this than the recent gold rush to identify synthetic routes to bicyclic arene bioisosteres, which are useful in medicinal chemistry. Five years ago, I can’t think of a single paper making these compounds; now, I can find nine in high-profile journals just from the past year or so (1,
2,
3,
4,
5,
6,
7,
8,
9).
Mechanistic and physical organic chemistry—another love of mine—present a tougher case, since in most cases the outcome of the studies is only knowledge. But I’m still not sure that this makes this field scientific! Let me illustrate why with an example.
An automotive engineer may be confused by why a given transmission is not working. He/she may formulate a hypothesis, take the transmission apart, perform various experiments on its constituent pieces, validate or disprove the initial hypothesis, and generally conduct a thorough mechanistic investigation to understand the origin of the problem. But does that make him/her a scientist?
The answer, I think, is no. The subject matter is not scientific, so no amount of scientific thinking can make the work science. Similarly, I’d argue that investigating the mechanism of a system invented and developed by humans—like a Pd-catalyzed cross-coupling reaction—doesn’t count as science. (Does application of the scientific method automatically make one a scientist? See below for a continued discussion.)
In contrast, something that I think is a truly scientific area of investigation is the study of enzyme structure and function. Despite extensive study and many Nobel prizes, we’re still learning about how enzymes operate and how they achieve such extraordinary reactivity and selectivity. (For an example of this sort of work, see Arieh Warshel’s review on electrostatic effects in enzyme catalysis, and references therein.)
I don’t think I understand all areas of chemistry well enough to fairly judge whether they’re better understood as engineering or science, so I’ll leave this as an exercise to the reader: What motivates your research? Are you mainly driven by a desire to understand the natural order of things, or do you aim to develop technology to make the world better? Both are important, and neither answer is bad—but if your main goal is inventing a new molecule, material, algorithm, or medicine, you might consider thinking of yourself as more of an engineer than a scientist.
Do Different Definitions Clarify Matters?
Since the claim that “most chemistry is engineering” is weird, we might consider alternative definitions to solve this problem.
One appealing definition: “a scientist is anyone who uses the scientific method.” As I discussed above, in the case of the automotive engineer, lots of people use the scientific method who clearly aren’t scientists: engineers, yes, but also detectives, doctors, and many other people. Indeed, according to this definition almost anyone who acquires data to shed light on a problem is “doing science.” So I don’t think this is a very good definition.
Another definition might be: “if you’re closely involved with science, you’re a scientist, even if the work you’re doing isn’t literally pushing the frontiers of knowledge forward.” I’m sympathetic to this definition, but I still find it hard to separate scientists and engineers here. What makes an engineer optimizing a new flow reactor less of a scientist than the chemist optimizing a new catalyst? Are they both scientists? What about people who work on chip design and fabrication, or people who design analytical instruments, or people who use them? I can’t find any clean way to divide scientists from engineers that recapitulates the conventional usage of the terms.
Why Does This Matter?
I think the root of this confusion is that the nature of scientific fields has changed over the past half-century. Organic chemistry hasn’t always been largely engineering; a century ago, the structure of natural products and the nature of the chemical bond were mysteries, truly the domain of science, and these issues were studied by chemists. As we’ve grown to understand our field better and better, our work has shifted from science to engineering—the true mysteries in chemistry are now few and far between, and the challenge facing today’s chemists is how to use centuries of accumulated knowledge to better society. But because of our lineage, we think of ourselves as scientists, and have managed to disguise the true nature of our work so well that we’ve deceived even ourselves.
By this point, it should be obvious that I don’t think science is superior to engineering. In fact, I’m glad to work in an area that’s largely engineering! But the way that an engineer ought to approach their work is different from the way a scientist ought to approach their work. In writing this piece, I came across a 1996 article by Frederick Brooks, who argued that computer science was better understood as an engineering discipline and defended the importance of this claim:
If our discipline has been misnamed, so what? Surely computer science is a harmless conceit. What’s in a name? Much. Our self-misnaming hastens various unhappy trends.
First, it implies that we accept a perceived pecking order that respects natural scientists highly and engineers less so, and that we seek to appropriate the higher station for ourselves. That is a self-serving gambit, hence dubious….
Second, sciences legitimately take the discovery of facts and laws as a proper end in itself. A new fact, a new law is an accomplishment, worthy of publication…. But in design, in contrast with science, novelty in itself has no merit. If we recognize our artifacts as tools, we test them by their usefulness and their costs, not their novelty.
Third, we tend to forget our users and their real problems, climbing into our ivory towers to dissect tractable abstractions of those problems, abstractions that may have left behind the essence of the real problem.
I think Brooks’s summary is simple and elegant. If we judge the value of our work based on the utility of our tools, rather than the novelty of our ideas, we’ll spend our time on different problems and get excited about different advances. There’s room for both scientists and engineers in chemistry—but at the margin, I think our field would benefit from becoming less like science, and more like engineering.
Thanks to Michael Nielsen, Joe Gair, Ari Wagen, and Michael Tartre for editing drafts of this post. Michael Tartre sent me the Richard Hamming quote, and Phil Brooks sent me his grandfather’s article.
Every year, our group participates in a “Paper of the Year” competition, where we each nominate five papers and then duke it out in a multi-hour debate. Looking through hundreds of papers in a few weeks is a great exercise: it helps highlight both creativity and its absence, and points towards where the field’s focus might turn next.
My picks are very personal—how could they not be?—and also biased towards towards experimental chemistry, owing to what our group focuses on. So, don’t take this as any attempt towards creating an objective list.
All the papers I really liked are listed below, with my top five listed in bold:
Pd-catalyzed C–H hydroxylation (Yu). Addresses a lot of my misgivings about C–H activation: directed by carboxylic acids, silver-free, scalable, and uses aqueous H2O2 (perhaps the best oxidant possible, after air).
Studying the mechanism of enantioselective enzymatic C–H amination (Yang Yang, Peng Liu). Surprisingly, radical rebound is enantiodetermining! I remember being puzzled by the mechanism of this reaction when it was first published; this is a very satisfying resolution. Cool isotope studies & ab initio molecular dynamics seal the deal. Pick 4/5.
wB97X-3c, the latest “composite method” (Grimme). If the reported speed and accuracy are true “in the wild,” every computational chemist ought to use this method. Pick 5/5.
For almost all Hartree–Fock-based computational methods, including density-functional theory, the rate-limiting step is calculating electron–electron repulsion. (This isn’t true for semiempirical methods, where matrix diagonalization is generally rate-limiting, or for calculations on very large systems.)
When isolated single molecules are the subject of calculations (as opposed to solids or periodic systems), most programs describe electronic structure in terms of atom-centered basis sets, which reduces the electron–electron repulsion problem to one of calculating electron repulsion integrals (ERIs) over quartets of basis shells. Framed this way, it becomes obvious why ERIs are the bottleneck: the number of ERIs will scale as O(N4), meaning that millions of these integrals must be calculated even for relatively small molecules.
I tried to get DALL-E to make a visual representation of integral screening; this was the best I got.
One big advance in electronic structure calculations was the development of integral screening techniques, the most popular of which is the “Schwartz inequality” (derived from the Cauchy–Schwartz inequality, but actually developed by Mario Häser and Reinhart Ahlrichs [EDIT: This is wrong, see correction at end!]). If we denote an ERI over shells A, B, C, and D as (AB|CD), then the Schwartz inequality says:
(AB|CD) ≤ (AB|AB)0.5 (CD|CD)0.5
This is pretty intuitive: each shell pair will interact with itself most, since it has perfect overlap with itself, and so the geometric mean of the interaction of each shell pair with itself is an upper bound for the interaction between the two shell pairs. (Why would (AB|AB) ever be a small value? Well, A and B might be super far away from each other, and so the “shell pair” has very little overlap is just negligible.)
This result is very useful. Since there are many fewer integrals of the form (AB|AB), we can start by calculating all of those, and then use the resulting values to “screen” each shell quartet. If the predicted value is less than some predefined cutoff, the integral is skipped. While these screening methods don’t help much with small molecules, where all of the shells are pretty close to each other, they become crucial for medium-sized molecules and above.
(What’s the cutoff value? Orca defaults to 10-8, Gaussian to 10-12, Psi4 to 10-12, and QChem to 10-8–10-10 depending on the type of calculation.)
The Schwartz inequality neglects, however, another way in which (AB|CD) might be very small: if (AB| and |CD) aren’t independently negligible, but are just really far away from each other. One elegant way to address this (out of many) comes from recent-ish work by Travis Thompson and Christian Ochsenfeld. They define an intermediate quantity M for each pair of shells, derived from different high-symmetry integrals:
MAC := (AA|CC) / ( (AA|AA)0.5 (CC|CC)0.5 )
MAC intuitively represents the distance between the two shells, and is guaranteed to be in the range [0,1]. Thompson and Ochsenfeld then use this quantity to propose an estimate of a shell quartet’s value:
This is no longer a rigorous upper bound like the Schwartz inequality, but it’s a pretty good estimate of the size of the integral.
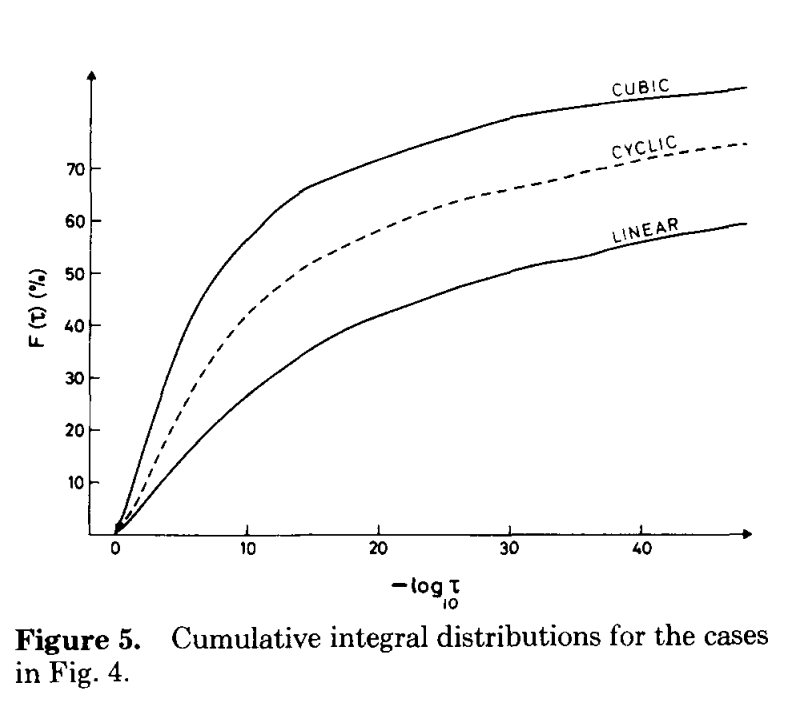
How much of a difference does this make in practice? To test this, I ran HF/STO-3G calculations on dodecane in the fully linear configuration. As shown by Almlöf, Faegri, and Korsell, linear molecules benefit the most from integral screening (since the shells are on average farther apart), so I hoped to see a sizable effect without having to study particularly large molecules.
Almlöf, Faegri, and Korsell, Figure 5. This paper is terrific.
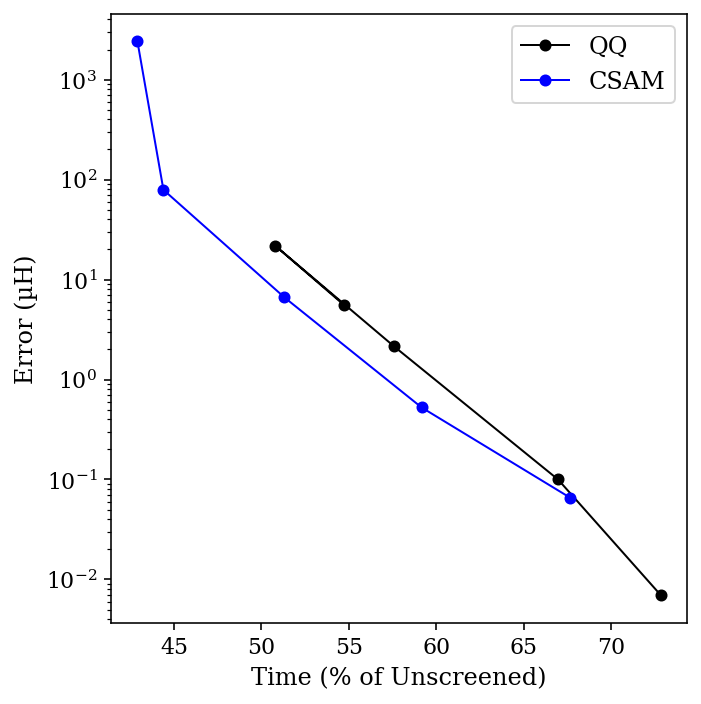
I compared both the Schwartz (“QQ”) bound and Ochsenfeld’s CSAM bound for integral thresholds ranging from 10-9 to 10-13, and compared the result to a calculation without any integral screening. The total time for the calculation, as a percent of the unscreened time, is plotted below against the error in µHartree (for the organic chemists out there, 1 µH = 0.00063 kcal/mol):
Comparing CSAM and QQ.
A few things are apparent for this data. First, even tight thresholds lead to dramatic speedups relative to the unscreened calculation—and with minimal errors. Secondly, the CSAM bound really does work better than the QQ bound (especially if you ignore the high-error 10-9 threshold data point). For most threshold values, using CSAM leads to about a 20% increase in speed, at the cost of a 3-fold increase in an already small error. Viewed visually, we can see that the Pareto frontier for CSAM (blue) is just closer to the optimal bottom-left corner than the corresponding frontier for QQ (black).
I hope this post serves to explain some of the magic that goes on behind the scenes to make “routine” QM calculations possible. (If you thought these tricks were sneaky, wait until you hear how the integrals that aren’t screened out are calculated!)
CORRECTION: In this post, I credited Mario Häser and Reinhart Ahlrichs with developing the Cauchy–Schwartz method for integral screening. A (famous) theoretical chemist who shall remain nameless reached out to me to correct the record—in fact, Almlöf included an overlap-based screening method in his landmark 1982 paper. To the untrained eye, this appears unrelated to ERI-based screening, but we are using Gaussian basis sets and so “one can therefore write the integrals in terms of overlaps,” meaning that what looked like a different expression is actually the same thing. (Section 9.12 of Helgaker/Jorgensen/Olsen's textbook Molecular Electronic Structure Theory, a book I sadly do not own, apparently discusses this more.)
The professor traced this back to Wilhite and Eumena in 1974, and ultimately back to the work of Witten in the 1960s. It is a pleasure to get corrected by those you respect, and I welcome any readers who find errors in my writing to reach out; I will do my best to respond and take blame as appropriate.
Meta-optimization has long been a focus of research in computer science, where new optimization algorithms can have an incredibly high impact (e.g. ADAM, one of the most commonly used optimizers for neural network training). More recently, the advent of directed evolution has made optimization methods a central focus of biocatalysis, since (in many cases) the efficacy of the reaction one discovers is primarily dependent on the efficacy of the optimization method used.
In contrast, it seems that meta-optimization has historically attracted less attention from “classic” organic chemists, despite the central importance of reaction optimization to so much of what we do. This post aims to show some of the ways in which this paradigm is changing, and briefly summarize some of what I consider to be the most interesting and exciting recent advances in chemical meta-optimization.
(This is a big and somewhat nebulous area, and I am certainly leaving things out or not paying due homage to everyone. Sorry in advance!)
Design of Experiments, and Dealing with Discrete Variables
Perhaps the best-known optimization algorithm in chemistry is “design of experiments” (DoE), which uses statistical methods to estimate the shape of a multiparameter surface and find minima or maxima more efficiently than one-factor-at-a-time screening. (DoE is a pretty broad term that gets used to describe a lot of different techniques: for more reading, seetheselinks.)
DoE has been used for a long time, especially in process chemistry, and is very effective at optimizing continuous variables (like temperature, concentration, and equivalents). However, it’s less obvious how DoE might be extended to discrete variables. (This 2010 report, from scientists at Eli Lilly, reports the use of DoE to optimize a palladium-catalyzed pyrazole arylation, but without many details about the statistical methods used.)
A nice paper from Jonathan Moseley and co-workers illustrates why discrete variables are so tricky:
How does one compare such different solvents as hexane and DMSO for example? Comparing their relative polarities, which is often related to solubility, might be one way, but this may not be the most important factor for the reaction in question. Additionally, this simple trend may not be relevant in any case, given for example that chlorinated solvents have good solubilising power despite their low-to-medium polarity (as judged by their dielectric constant). On the other hand, the high polarity and solubilising power of alcohols might be compromised in the desired reaction by their protic nature, whilst the “unrelated” hexane and DMSO are both aprotic.
In summary, replacing any one of the discrete parameters with another does not yield a different value on the same axis of a graph, as it would for a continuous parameter; instead it requires a different graph with different axes which may have no meaningful relationship to the first one whatsoever. This means that every single combination of catalyst/ligand/base/solvent is essentially a different reaction for the same two starting materials to produce the same product. (emphasis added)
The solution the authors propose is to use principal component analysis (PCA) on molecular descriptors, such as “measurable physical factors (e.g., bp, density, bond length), or calculated and theoretical ones (e.g., electron density, Hansen solubility parameters, Kamlet–Taft solvent polarity parameters),” to convert discrete parameters into continuous ones. This general approach for handling discrete variables—generation of continuous molecular descriptors, followed by use of a dimensionality reduction algorithm—is widely used today for lots of tasks (see for instance this paper on DoE for solvent screening, and my previous post on UMAP).
Choosing Intelligent Screening Sets
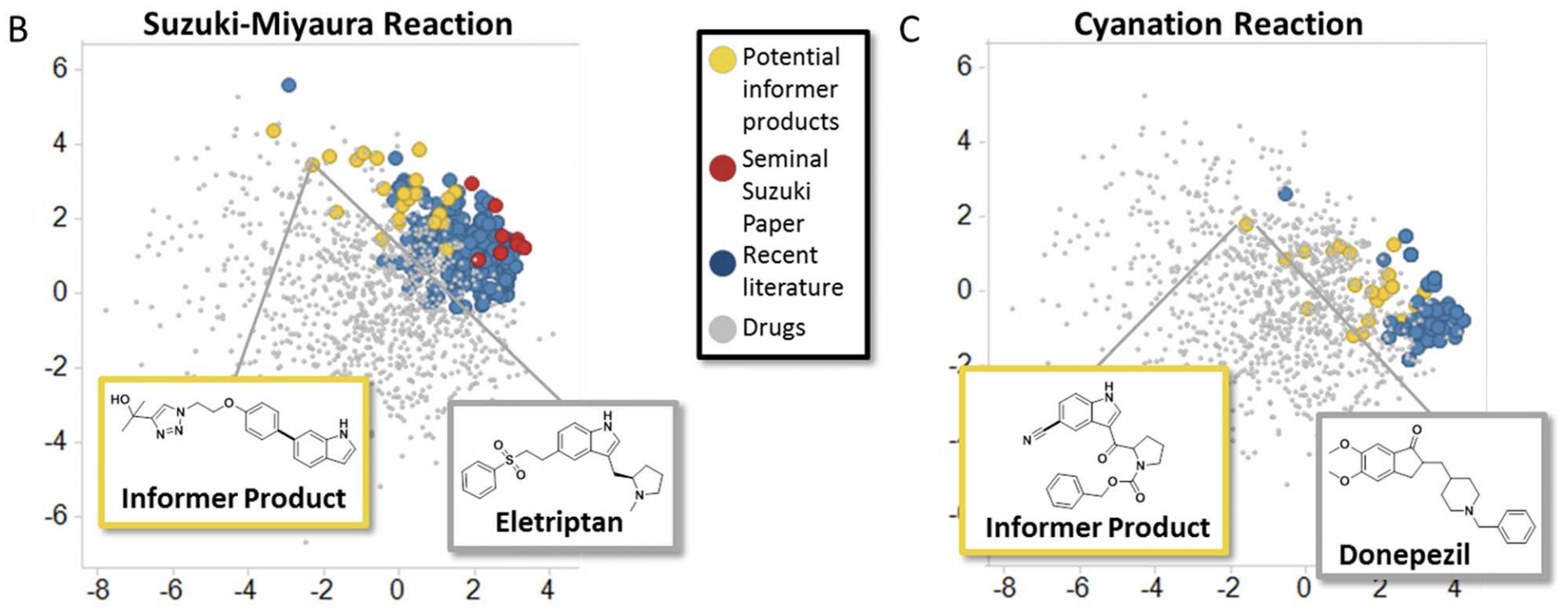
With continuous descriptors for formally discrete variables in hand, a natural next step is to use this data to choose catalyst/substrates that best cover chemical space. (This can be done with several algorithms; see this paper for more discussion) In 2016, this technique was popularized by the Merck “informer library” approach, which generated sets of aryl boronic esters and aryl halides that could be used to fairly evaluate new reactions against complex, drug-like substrates. (See also this recent perspective on the Merck informer libraries, and similar work from Matt Sigman a few years earlier.)
Illustration of the Merck informer library (yellow) in chemical space, compared to drugs (grey) and compounds from recent literature (blue).
While the Merck informer libraries were intended to be shared and used by lots of research groups, recently it’s become more common for individual research groups to design their own project-specific screening sets. Abbie Doyle and co-workers kicked this off in 2022 by using DFT-based descriptors, UMAP dimensionality reduction, and agglomerative hierarchical clustering to generate a maximally diverse set of commercial aryl bromides. Other groups soon followed suit: Karl Gademann used this approach to study bromotetrazine cross coupling, while Marion Emmert and co-workers at Merck employed similar methods to investigate azole carboxylation. (I’ve also used this approach for substrate selection!)
This approach can also be used to design intelligent sets of catalysts/ligands at the outset of a screening project. Using their “kraken” dataset of phosphine properties, Tobias Gensch and Matt Sigman proposed a set of 32 commercially available ligands which aims to cover as much of phosphine chemical space as possible in an initial screen. Jason Stevens and co-workers combined this idea with the substrate-selection methods from the previous paragraph to perform a detailed study of Ni-catalyzed borylation under many conditions, and tested a variety of ML models on the resulting dataset. (Scott Denmark and co-workers have also used a variant of this idea, called the Universal Training Set, to initialize ML-driven reaction optimization.)
New Optimization Algorithms
As in every area of life, ML-based approaches have been used a lot for optimization recently. This isn’t new; Klaus Jensen and Steve Buchwald used machine learning to drive autonomous optimization in 2016, and Richard Zare published a detailed methodological study in 2017. Nevertheless, as with computational substrate selection, these techniques have come into the mainstream in the past few years.
I mentioned the work of Scott Denmark on ML-driven optimization before, and his team published two more papers on this topic last year: one on atropselective biaryl iodination, and one on optimization of Cinchona alkaloid-based phase transfer catalysts. In particular, the second paper (conducted in collaboration with scientists at Merck) illustrates how an ML model can be updated with new data as optimization progresses, allowing many sequential rounds of catalyst development to be conducted.
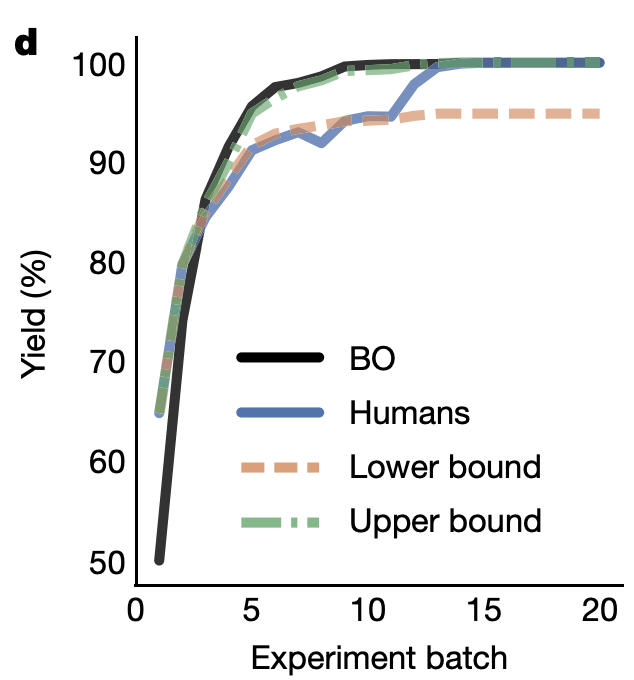
Abbie Doyle’s group has done a lot of work on using Bayesian optimization (BO) to drive reaction optimization. Their first paper in this area illustrated the capacity of BO to avoid spurious local minima, and went on to validate this approach in a variety of complex problems. Even better, they compared the results of BO to chemist-guided optimization to see if computer-driven optimization could outcompete expert intuition. To quote the paper:
In total, 50 expert chemists and engineers from academia and industry played the reaction optimization game (Fig. 4c). Accordingly, the Bayesian reaction optimizer also played the game 50 times (Fig. 4b), each time starting with a different random initialization. The first point of comparison between human participants and the machine learning optimizer was their raw maximum observed yield at each step during the optimization. Humans made significantly (p < 0.05) better initial choices than random selection, on average discovering conditions that had 15% higher yield in their first batch of experiments. However, even with random initialization, within three batches of five experiments the average performance of the optimizer surpassed that of the humans. Notably, in contrast to human participants, Bayesian optimization achieved >99% yield 100% of the time within the experimental budget. Moreover, Bayesian optimization tended to discover globally optimal conditions (CgMe-PPh, CsOPiv or CsOAc, DMAc, 0.153 M, 105 °C) within the first 50 experiments (Fig. 4b). (emphasis added)
Average yield per batch from Bayesian optimization (black) vs. humans (blue), showing how Bayesian optimization outcompetes humans despite a worse start.
Their subsequent work has made their optimization app available online, and illustrated the application of this strategy to other reactions.
Closely related is this work from Aspuru-Guzik, Burke, and co-workers, which uses a “matrix-down” approach to choosing representative substrates for the Suzuki reaction (similar to the substrate-selection algorithms discussed previously). The selected substrates are then subjected to automated high-throughput screening guided by an uncertainty-minimizing ML model (i.e., new reactions are chosen based on the regions of chemical space that the algorithm has the least knowledge about; this is similar to, but distinct from, Bayesian optimization). This is a pretty interesting approach, and I hope they study it further in the future. (Aspuru-Guzik has done lots of other work in this area, including some Bayesian optimization.)
Finally, two papers this year (that I’m aware of) put forward the idea of using multi-substrate loss functions for optimization: our work on screening for generality and a beautiful collaboration from Song Lin, Scott Miller, and Matt Sigman. These papers used “low-tech” optimization methods that are familiar to practicing organic chemists (e.g. “screen different groups at this position”), but evaluated the output of this optimization not based on the yield/enantioselectivity of a single substrate but on aggregate metrics derived from many substrates. The results that our groups were able to uncover were good, but I’m sure adding robotics and advanced ML optimization will turbocharge this concept and find new and better catalysts with truly remarkable generality.
Conclusions
Reaction optimization is a common task in organic chemistry, but one that’s commonly done without much metacognition. Instead, many researchers will screen catalysts, substrates, and conditions based on habit or convenience, without necessarily dwelling on whether their screening procedure is optimal. While this may work well enough when you only need to optimize one or two reactions in your whole graduate school career (or when acquiring each data point takes days or weeks), ad hoc strategies will at some point simply fail to scale.
Organic chemistry, long the realm of “small data,” is slowly but inexorably catching up with the adjacent sciences. As progress in lab automation and instrumentation makes setting up, purifying, and analyzing large numbers of reactions easier, experimental chemists will have to figure out how to choose which reactions to run and how to handle all the data from these reactions, using tools like the ones discussed above. Like it or not, data science and cheminformatics may soon become core competencies of the modern experimental chemist!