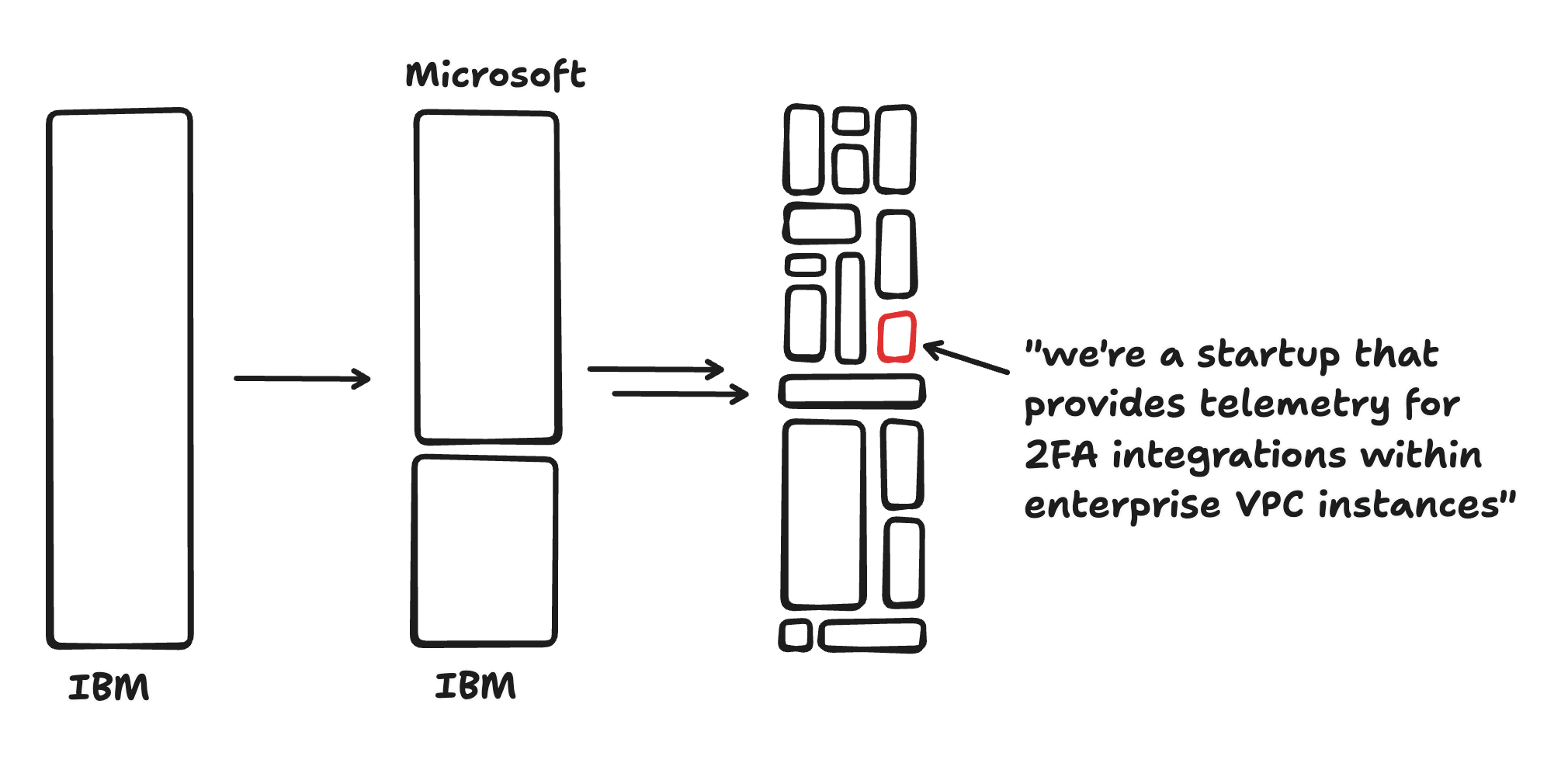
Long ago, there were no software companies. In the age of System/360, vertically integrated companies like IBM were responsible for virtually all aspects of the end product they sold, from hardware to operating system to end-user applications. Then, the value chain started to diversify: Microsoft allowed software and hardware to become decoupled, and then a variety of application-specific companies started to pop up (like Lotus). Today the software ecosystem is incredibly diverse, and even simple software companies typically rely on a web of vendors and sub-vendors.
I call this process “horizonalization,” because it reflects a move from vertically integrated monoliths towards an ecosystem of companies aimed at horizontally integrating a given capability:
We can imagine two reasons why this transformation might have happened:
The technology got more complex. Software is much more complex than it used to be, and it’s no longer possible for most teams to build the entire stack themselves—as complexity rises, more teams will choose “buy” over “build.”
The market got larger. There’s a certain minimum practical size for companies, and as the market grew it could accommodate more vendors.
Ronald Coase’s 1937 paper “The Nature of the Firm” proposes a theoretical framework that will be useful for this discussion. Coase argues that the natural size of companies is an equilibrium between competing factors. Making companies bigger makes work easier by diminishing “transaction costs”: doing work with external parties requires coordination, NDAs, invoices, taxes, and so on, while doing work with someone inside the same company is comparatively easy. Unfortunately, larger companies also become less efficient, because “the entrepreneur fails to place the factors of production in the uses where their value is greatest” (pp. 394–395), i.e. managers do a bad job. So in practice these opposing forces balance and companies end up at a size somewhere between “everyone is their own company” and “there’s only one company.”
Viewed this way, horizontalization is a natural response to increasing market size and complexity. As the market became big enough that there could be “a database company” or “an ads company,” it became advantageous for these capabilities to become their own firms rather than stay part of a single monolithic ur-company. These same firms, once independent, were able to innovate and find new markets and technologies more rapidly than they could have before, further growing the sector and continuing the process.
* * *
As readers may have inferred from the title, I think the same transformation is happening in biotech and drug discovery today. Fifty years ago, drug discovery was almost entirely vertically integrated. New biotech companies had to rebuild almost every capability themselves from scratch (The Billion-Dollar Molecule documents Vertex doing this in the 1980s).
In the 2000s and 2010s “virtual biotech” companies that outsourced most or all of the chemistry and biology work to CROs and CDMOs became common—see this 2012 article from Derek Lowe, which discusses the change in the industry. These virtual biotechs often had no aspiration to be around forever; many single-asset virtual biotechs aimed to pursue a given biological target through early-stage clinical trials and then get bought by pharmaceutical companies, who would fund Phase III trials and subsequent manufacturing & distribution.
Not coincidentally, this time period also saw CROs and software companies like Schrodinger and Benchling become important ecosystem vendors. As the expected life cycle of therapeutics companies decreased, it became important to conserve cash and not build out unnecessary infrastructure that wouldn’t pay for itself within a few years. Increasing amounts of research started to be done through research-as-a-service models, and the burden of building efficient high-throughput research processes shifted away from internal teams and towards vendors. Basically, the pendulum moved away from “build” and towards “buy.”
Today, I think this trend is continuing or even accelerating. Here’s a few case studies:
Plasmidsaurus is a company that sequences DNA and RNA really cheaply and really quickly. That’s it! (For more details, see the Owl Posting writeup.)
Adaptyv is building a “fully automated protein foundry,” or essentially a next-gen protein CRO that generates wet-lab data to validate or train ML models.
Cradle is a protein-engineering-as-a-service company that helps therapeutic and industrial customers design better proteins.
BioRender sells software to make beautiful biological figures. You might think this sounds like an incredibly niche business, but a recent secondary round valued the company at 900M!
And, since I started working on this essay, model companies like Noetik, Chai, and Boltz have all announced massive partnerships with pharma.
Despite these examples, horizontalization is harder in biotech than in software. Broadly, transaction costs are higher—pre-clinical IP is very sensitive, making companies more suspicious of outside vendors—meaning that it’s harder to partner externally and easier to bring capabilities in-house. The total biotech market is also smaller, meaning that there are fewer potential customers for any new vendor and thus fewer possible niches.
But the growing complexity of drug discovery in the era of AI and lab automation counteracts these trends somewhat, because all this complexity can only be managed by outsourcing capabilities to vendors. Imagine trying to build the equivalent of the OnePot self-driving lab within every new oncology startup! Every new layer of complexity creates opportunities for vendors to decrease unit costs by increasing upfront capital expenditure; scale economies create the incentives for horizontalization.
* * *
I think that horizontalization is good for the world. One reason is just that horizontalization creates efficiency—this is a pretty obvious point, going back all the way to Adam Smith, but it still needs to be said. Companies that specialize in a given technology, service, or product can typically do a better job than a team trying to add yet another random capability. That’s why Plasmidsaurus is better at sequencing things than you are.
But horizontalization also increases the field’s institutional memory. Early-stage biotech has weird company dynamics—as discussed above, most therapeutics companies survive only a handful of years, ending their existence either through acquisition or quiet dissolution. (In many cases the preclinical research team disbands even if the legal entity technically survives.) This means that there’s a lot of tacit institutional knowledge which gets lost or dispersed. A DNA-encoded library team might have developed a set of protocols, workflows, and practices which led to incredible performance, but if their company lays off all the research staff, then all this has to be recreated de novo wherever these scientists work next.
Coupled with the atmosphere of secrecy in the industry, the overall effect is that best practices are slow to diffuse in early-stage drug discovery. Horizontalization provides an opportunity to fix this. To use the specific example of DNA-encoded libraries (DELs) again, companies like Om and Leash can develop DEL-related expertise that far exceeds what any single therapeutics can achieve, and keep this knowledge and “process power” alive longer than the typical lifespan of a therapeutics company.
If horizontalization is happening, and will happen more in the future, what are the consequences? Here’s some speculation:
1. There are more viable biotech-adjacent businesses than people think. Each new biotech-adjacent company that gets created becomes a new potential customer for another vendor, increasing total market liquidity and creating new opportunities for innovation. It’s not quite clear how far these trends will go, but I think the prevailing VC sentiment that “the only way to monetize biotech innovation is through therapeutic assets” is already wrong.
2. Transaction costs will matter more. Right now, it’s pretty easy to start using a different software vendor (just sign up and point your code at the right API endpoint) but relatively difficult to start working with a new vendor in biotech. There are good reasons for this. As discussed above, drug discovery is a very IP-sensitive industry, and the wrong chemical structure in the wrong hands might cost millions or even billions of dollars.
Rejecting all external vendors and internalizing every function can’t be the right answer, as increasing complexity will make monoliths less and less capable over time. Instead, the industry needs to find ways to lower transaction costs without compromising on IP or security. The company that figures this out will be a big winner.
Both of these predictions might be wrong! But, at a high level, I think horizontalization is both inevitable and beneficial; I look forward to the day when biotech has as many interesting and competent vendors as software, and I’m working to try and make Rowan one of those vendors.
Thanks to Ari Wagen for helpful conversations on these topics and for editing drafts of this essay.
Strangely, Roberts’ Napoleon reminded me a lot of Elon Musk—incredible drive and energy, mind-melting attention to detail, and a culture of micromanagement and direct control which perhaps more than anything else drove him to ruin. (I hope Elon’s story has a happier ending.)
#2. Magda Szabo, The Door #3. Marc Benioff, Behind The Cloud #4. James Clavell, Shogun
I distrust most historical fiction, but this book was actually good. Hosokawa Gracia is one of history’s great Christian heroes.
#5. M. Mitchell Waldrop, The Dream Machine #6. David Sirlin, Playing to Win
Many ex-academic startup founders should read this book.
#7–8. Solvej Balle, On the Calculation of Volume (volumes 1 & 2)
As recommended by Santi Ruiz; a great read about how the British state adapted and transformed during the Napoleonic wars. Roberts credits the British privatization of the military supply apparatus to much of Britain’s success in the war, which I found interesting. This book also helped me understand why government procurement is so crucial and so regulated today.
#10. Chris Voss, Never Split the Difference #11. James Scott, Seeing Like a State
This book is ubiquitous in grey-tribe discourse these days, which pushed me to avoid reading it because it seemed overrated. It turns out I was wrong and it’s properly rated—Scott’s way of thinking gave me a whole new set of mental models for legibility, system fragility, and how we structure knowledge. Definitely worth a read.
#12. F. L. Ganshof, Feudalism #13. Werner Krusche, And God Spoke with His People #14. David Chandler, The Campaigns of Napoleon
While the two previous Napoleon books I read were very good, this book is one of the best books I’ve read on any topic. Many biographies (including Roberts’ above) try to avoid getting side-tracked by military history, preferring instead to focus on describing the man behind the campaign. Chandler does the opposite—he focuses only on the military aspect of Napoleon’s life and isn’t afraid to examine his historical models, his moments of genius, and his myriad mistakes.
Paradoxically, this focus ends up giving the reader a clearer picture of Napoleon as a person, because military campaigns were where he devoted the bulk of his energy and intellect. The book also has incredibly beautiful maps; I learned a lot of European geography trying to follow the various campaigns.
Eriksen is a weird guy; at once a hardcore RETVRN poaster and an avowed practicing bigamist. I guess polygamy is the most Lindy thing of all if you go back far enough?
#16. Eric Raymond, The Cathedral and the Bazaar
Venerable but still the best piece I’ve read on the dynamic between open- and closed-source software. Raymond argues that the open-source-software community operates as a gift economy, and that there are powerful incentives for infrastructure/protocols to become open (but not applications). This book has been useful in informing how we think about open-source strategy at Rowan.
#17. Andy Weir, Project Hail Mary
I really disliked this book. Weir’s science fiction is grimly impersonal in a way that makes me sad—the fiction centers on science, not people, and even though I like science I prefer my novels to be about people.
#18. Martyn Rady, The Middle Kingdoms
As recommended by Tyler Cowen. A good overview of Central European history, although it left me wanting more details on almost everything.
#19. Vernor Vinge, A Deepness in the Sky #20. John Mark Comer, Practicing The Way
This book was recommended to me, but I’m not a huge fan. Other people have written good critical reviews of this book—see inter aliaKevin DeYoung and Wyatt Graham—so I’ll leave it at that.
#21. Phillips O’Brien, How the War Was Won
O’Brien argues that the popular narrative around World War II is wrong, and that brute economic output as expressed through air and sea power was the primary factor leading to Allied victory. It pairs nicely with Britain Against Napoleon (book #9) and has influenced my thinking about present and future wars.
#22. Ronald Rolheiser, Domestic Monastery
The central idea of this book is that the mayhem of family life can create spiritual formation in much the same way that monastic discipline does—through constant reminder that our life and time is not ours, but should be spent in love and service. This idea is powerful.
#23. Five Views on Law and Gospel (by various authors)
I tried and failed to write a full blog post about this book for months. Briefly—the story of the Bible, dramatically abbreviated, goes something like this (not theology advice):
God makes people, who live in right relationship with him.
But the people sin, breaking this relationship, and death enters the world.
God gives his people laws, like the Ten Commandments, to be reconciled to him.
But people are sinful and don’t obey the laws.
God sends his Son to live a perfect life, die to pay the price for our sin, and be raised to eternal life.
People can now be reconciled to God, even though they’re still sinful.
We await the day when God will make the world anew without sin.
This basic outline is pretty accepted by all Christian denominations, although people might quibble with the details—Catholics and Protestants disagree on the mechanics of #6, for instance. A critical reader might, however, have some questions. What’s the point of #3 and #4 above? If God’s people never followed the law, why was it there at all? And was that just a weird tangent in the history of salvation, or do these laws still matter at all today?
While these questions may seem rudimentary, they’re actually quite controversial—John Wesley wrote that “there are few subjects within the whole compass of religion so little understood as this.” Martin Luther and John Calvin, two giants of the Reformation, wrote at length about these questions, and they continue to be debated by Christian scholars to this day. But unlike other open theological questions, like Calvinism vs. Arminianism, many Christians don’t even realize that there are a range of opinions here or that people disagree at all on these issues.
This theological issue also has important real-world consequences. If the law of Moses has enduring moral validity, then the Old Testament’s teachings on the Sabbath, fasting, tithing, and usury might still be binding to modern Christians; if not, then the teachings probably aren’t. More dramatically, movements like Christian Reconstructionism seek to rebuild all of modern society around the Mosaic Law—which has pretty big implications. These movements have gained a lot of traction on the right in recent years. A recent Politico article on the influential “New Right” pastor Doug Wilson cited R. J. Rushdoony, the “father of Christian Reconstructionism,” as a key intellectual influence (emphasis added):
In response, [Wilson] started reading books by a group of conservative Reformed theologians — writers like Francis Shaeffer, who posited that all knowledge was grounded in the truth of Biblical revelation, and R.J. Rushdoony, who argued that all Biblical law, including the Old Testament law, still applied to the contemporary world.
(Grouping Schaeffer with Rushdoony here is wild.)
Five Views on Law and Gospel directly addresses the question of how law and gospel intersect. In the book, five Protestant theologians (Willem VanGemeren, Greg Bahnsen, Wayne Strickland, Walter Kaiser, and Douglas Moo) each write an initial opinion piece, and then every other author responds with their own essay. This makes for a fascinating but somewhat schizophrenic read—the argumentation is scattered across 25 different essay-length pieces, so writing a proper review proved to be substantially more intellectual effort than I could commit. (My draft blog post is 11 pages of increasingly inchoate theological ramblings.)
If you’re interested in the topic, this is a great book.
#24. Hillaire Belloc, The Great Heresies #25. John Mark Comer, The Ruthless Elimination of Hurry
A helpful overview to the parables of Jesus, with useful literature review broken down by parable. (I read this to prepare for hosting a study of the parables, and found it useful.)
#27. Dane Ortlund, Gentle and Lowly #28. Yukio Mishima, The Sailor Who Fell from Grace with the Sea
Just fantastic.
#29. Anthony Kaldellis, The New Roman Empire
As recommended by Tyler Cowen. A great introduction to the history of the “Byzantine” empire (a term which Kaldellis rejects); unfortunately, his takes on church history seem pretty suspect overall, which makes me uncertain how much to trust his opinions on other topics.
I recommended this book to someone else, who agreed that “his church stuff is rough” and wrote back:
[Kaldellis] has me reflecting on the modern failing for people to believe that humans do act out of ideological belief, i.e. it’s not just a mask for some other desire.
I think this is right. It’s impossible to understand Athanasius of Alexandria without first accepting that he’s primarily a theological thinker, and that everything else flows out of his faith (and not vice versa). Dialectical materialism this is not…
#30. Eric Berger, Reentry #31. Reed Hastings, No Rules Rules #32. Emmanuel Le Roy Ladurie, Montaillou: The Promised Land of Error
#34. William Shakespeare, Coriolanus #35. Donald Braben, Scientific Freedom: The Elixir of Civilization
I’m a bit skeptical of Braben’s view of scientific incentives; I tend to favor Eric Gilliam’s view that some pressure from real-world applications can give scientists a push towards useful discoveries, while Braben seems to think that just letting scientists follow their curiosity without constraints or incentives is key. Maybe I’m too cynical, but this feels like Emile for science.
#36–39. Orson Scott Card, the Ender’s Shadow series #40. B. B. Warfield, The Plan of Salvation #41. Helen Castor, The Eagle and the Hart
#42. William Shakespeare, Richard II #43. Alfred Bester, The Stars My Destination #44. Michael Kempe, The Best of All Possible Worlds: A Life of Leibniz in Seven Pivotal Days
#46. Bryan Burrough and John Helyar, Barbarians At The Gate
An account of the 1988 leveraged buyout of RJR Nabisco. I didn’t realize that “corporate finance thriller” was a genre I would love, but I couldn’t put this book down—I’m upset I didn’t read it sooner.
Days of Rage, a later book by Burrough, is also excellent.
#47. Dan Wang, Breakneck
The first book I’ve ever pre-ordered. I generally thought this book was good and interesting throughout; it leaves me with a lot of questions, but that’s to be expected. Wang’s chapter on the one-child policy was horrifying; from a consequentialist point of view, Paul Ehrlich must be one of the world’s greatest villains.
#48. Soren Kirkegaard, Fear and Trembling
Read in preparation for my trip to Copenhagen.
#49. Ivan Illich, Gender #50. Ivan Illich, Deschooling Society
Mary Harrington has recommended Illich’s writings before on her Substack (e.g.), which pushed me to read these books. Both were thought-provoking and worth reading; I’m still digesting the ideas and expect to be for some time.
To give a flavor of the argument: in Deschooling Society Illich argues that school and other modern institutions confuse process and substance, making our values like health and learning "little more than the performance of the institutions which claim to serve those ends" and creating “psychological impotence and modernized misery.” I’m not fully convinced by his proposed solutions, but I think a lot of his criticisms of formalized education ring true and dovetail nicely with Seeing Like a State (book #11).
#51. Robert Hughes, The Fatal Shore
As recommended by Misha Saul. This one shocked me a bit—I had no idea how bizarre and horrible the early history of Australia was. Well worth a read.
#52. Robert Massie, Peter the Great: His Life and World #53. Alistair MacIntyre, After Virtue
Sadly, another book I only read because of an obituary.
MacIntyre opens After Virtue by comparing ethical discourse in our society to a post-apocalyptic world in which people use relics of a distant age without understanding how they work or where they come from (a la Canticle for Leibowitz). As someone without many natural philosophical inclinations, I found parts of this book a bit tedious—but I’ve found myself bringing it up constantly in conversation and argumentation since I finished, which is high praise.
#54. Tim Blanning, Frederick the Great #55. Iain Banks, Consider Phlebas #56. Joshua McNall, The Mosaic of Atonement
McNall argues that most Protestants’ understanding of penal substitutionary atonement is wrong, and that we should be thinking more about Christus Victor. I didn’t love the writing, but the argument is solid.
#57. Josef Pieper, A Brief Reader on the Virtues of the Human Heart
As recommended by Santi Ruiz.
#58. Joel Mokyr, A Culture of Growth
Our new Nobel Laureate in Economics! A few observations from this book:
Mokyr highlights Francis Bacon and Isaac Newton as the top figures in the Scientific Revolution. Newton obviously remains highly rated, but I know very little about Francis Bacon, perhaps because his ideas are so dominant today that nobody bothers to read him?
Mokyr points out that many scientific societies were originally founded around the love of practical knowledge for the betterment of society—what happened, folks? Scientists’ narrow-minded conception of what science is or should be is holding them back (previously on the blog).
Mokyr argues that Europe experienced the industrial/scientific revolution because it maintained a unified intellectual culture despite political fragmentation, leading to economies of scale in ideas without the capacity for any single actor to repress or censor ideas (as happened in Ming China). I’ve heard variants of this argument before, but Mokyr makes it particularly well.
Mokyr also points out that the “republic of letters” (and academia today) operates as a status-focused gift economy—just what Raymond argues about open-source software (book #16, vide supra). I’d never made this connection before.
#59. Tyler Cowen, Stubborn Attachments #60. Jerusalem Demsas, On the Housing Crisis #61. Thomas Pynchon, Inherent Vice
I also watched the movie, which was actually quite good.
#62. George Eliot, Middlemarch
Yeah, okay, I admit I’m a few months (or years) late to the party here. Middlemarch is a good book, but I don’t think it’s “the best novel ever” like some have said; I prefer either The Brothers Karamazov or Infinite Jest, to say nothing of dark-horse candidates like Kristen Lavransdatter. But I don’t regret reading it. Eliot captures the emotion of unsatisfied ambition and personal disappointment perhaps better than anyone else I’ve read?
#63. Gary Kinder, Ship of Gold in the Deep Blue Sea
I also didn’t finish a few books:
I hated John Barth’s Giles Goat-Boy so much that I stopped reading after a few hundred pages. I truly don’t know what people see in this book.
I read most of Tim Keller’s The Meaning of Marriage, which was the suggested reading for a class I helped out with at church, but missed a few chapters in the middle.
I started Calvin’s Institutes but—shocker—didn’t finish it. I’m reading the Battles translation, which came highly recommended, and I’m liking it so far.
I’ve started D. A. Carson’s commentary on Matthew but haven’t made much progress yet. Next year!
And I’m partway through Roger Chickering’s history of the German Empire (1871–1918), which is good so far.
If you’ve made it this far, thanks! I find myself in a contemplative mood, and I want to share (1) a brief reflection on the year’s events, (2) a few thoughts around ambition, and (3) some of the cocktails that Chloe and I enjoyed in 2025
* * *
The past year was a big one for our family. In no particular order: our company grew a lot (and in too many ways to recount here); I spoke at three universities and five conferences; my wife quit her job; we helped lead two marriage classes and a Romans bible study; we planned and took our first “solo” international trips, to Croatia and Denmark; I made Macau tamarind pork constantly; I broke my foot and got rhabdo; my son learned how to read; my daughter learned how to speak; and we had a third child (now almost a month old). Looking back over all of this, I think the undeniable conclusion is that I’m becoming middle-aged.
If you’ve been a part of this journey at all—thanks! I’m incredibly grateful to lead a busy and interesting life and for all the persons who populate it, both professionally and personally.
* * *
I’ve become more bothered by the cultural discourse around ambition. To both east- and west-coast crowds, ambition is something that’s good. We celebrate the founder tackling an ambitious problem, the politician with bold new ideas, or the writer aiming to reshape how society thinks about a given topic and achieve “thought leadership.” And if we define ambition simply as the desire to make the world better than it is, then it seems obvious that we should all be as ambitious as possible.
But this doesn’t seem to comport with other sources. The Bible verse I’ve found myself reflecting on is 1 Thess 4:10–12 (emphasis added):
But we urge you, brothers, to do this more and more, and to aspire to live quietly, and to mind your own affairs, and to work with your hands, as we instructed you, so that you may walk properly before outsiders and be dependent on no one.
Paul is saying something surprising: that we ought not to try and disrupt the world as much as possible, but instead we should be content to live inwardly focused “quiet lives” where we tend our own gardens and keep to ourselves. Living quietly should be our aspiration. It may not be something we can always achieve, but it’s the best-case scenario.
So, is ambition bad? Paul himself is clearly not a person devoid of ambition; 1 Corinthians 9 is fully aligned with the “founder mode” / agency memes. I don’t think this passage means that all outward-focused ambition is necessarily bad. But Paul does remind us that our first and primary ambition should be inward, aimed at the renovation of ourselves (“Always be killing sin, or it will be killing you”). Life may push other ambitions upon us—but if we had no other ambitions, this alone would be enough.
(A full literature survey would take too long, but it’s worth noting that ambition isn’t typically a fantastic character trait in pre-modern literature: contrast Macbeth’s “vaulting ambition” to the likes of Cincinnatus.)
Unfortunately, everyone today seems in love with ambition. Without naming names, I can think of plenty of startup founders and VCs who espouse a Christian pro-family worldview while expecting themselves, their employees, and their portfolio companies to live and work in such a way that makes it impossible to uphold family obligations. This is bad.
I wish that these people and many others would be willing to be less ambitious externally—revenue, impact, followers, cachet—and would instead be ambitious about virtue or something similar. “For what does it profit a man to gain the whole world and forfeit his soul?” Similar things could be written about the modern church’s love of growth metrics and other legibility-focused outcomes.
Eliot says it better than I can. To quote from the end of Middlemarch, which looks back on the life of Dorothea Brooke:
Her full nature, like that river of which Cyrus broke the strength, spent itself in channels which had no great name on the earth. But the effect of her being on those around her was incalculably diffusive: for the growing good of the world is partly dependent on unhistoric acts; and that things are not so ill with you and me as they might have been, is half owing to the number who lived faithfully a hidden life, and rest in unvisited tombs.
May we all aspire to such an epitaph.
* * *
And, finally, a few cocktail recipes to close out the year:
Cynar Plane
0.5 oz Cynar 0.5 oz Aperol 0.5 oz bourbon (Evan Williams Bonded, typically) 0.5 oz lemon juice
Shake and serve with a big ice cube.
This is a variant on Sam Ross’s Paper Plane that substitutes Cynar for Amaro Nonino; Nonino is expensive and Cynar is delicious.
Little Giuseppe
1 oz Cynar 1 oz Punt e Mes A dash of Angostura bitters A squeeze of lemon juice A pinch of kosher salt Giant ice cube
Mix the Cynar and Punt e Mes together in an Old Fashioned glass, then add the bitters and lemon juice. Stir, add the big ice cube, and sprinkle the salt on top of the ice.
My wife doesn’t really like this drink, but I love it.
Mosquito
0.5 oz Aperol 0.5 oz bourbon (Evan Williams Bonded, typically) 0.5 oz lime juice 0.5 oz ginger syrup
Shake and serve with a big ice cube.
Another Sam Ross drink, not so dissimilar to the Cynar Plane above—this one is pretty low ABV, which is nice. I make ginger syrup by blending and filtering a 1:1:1 mixture of chopped ginger root, water, and sugar. It keeps for a few days but not indefinitely, so drink up!
Daiquiri
2.0 oz rum(s) 0.5 oz lime juice 0.5 oz simple syrup
Shake and serve with a big ice cube.
Following advice from my old Merck collaborator Spencer McMinn, I’ve been making daiquiris with a modification of the original Embury recipe: 2.0 oz rum, 0.5 lime juice, and 0.5 oz simple syrup. You can basically use any rum you want here—this is a very rum-forward drink, so nicer rums aren’t lost like they would be in a Jungle Bird. I like the 8-year Rhum Barbancourt or Smith & Cross, and a blend isn’t bad here either.
Jungle Bird
3.0 oz rum (Flor de Caña 4 yr or similar) 1.5 oz Campari 1.0 oz lime juice 70ish g frozen pineapple 1.5 tbsp brown sugar 1.0 tbsp water
Blend until smooth and serve: the frozen pineapple means you don’t really need ice, although you can add some if you want. On small scale, I typically just use an immersion blender and a jar.
The above measurements are admittedly a bit of a mess—this is adapted from a much larger recipe, which uses 0.6 L of rum and a full pound of pineapple. Still, this is approximately correct, and the drink is flexible enough that you can easily flex anything up or down without messing it up.
Most Jungle Bird recipes you find floating around on the internet are pretty different from this: the pineapple is juice, there’s more of it, and there’s less Campari. I think this is much better. The chunks taste better and give the drink a lovely creamy texture, while the extra Campari balances the sweetness of the other ingredients.
October 21, 2025The Vision of The Valley of The Dry Bones, Gustave Doré (1866)
Last week I had the privilege of attending the 2025 Progress Conference, which brought together a diverse cadre of people working on progress, metascience, artificial intelligence, and related fields. I was surprised by how optimistic the median attendee was about AI for science. While some people inside science have been excited about the possibilities of AI for a while, I didn’t expect that representatives of frontier labs or think tanks would expect scientific progress to be the biggest near-term consequence of AI.
At this point it’s obvious that AI will affect science in many ways. To name just a few:
LLMs are changing the way that we write and interact with code, so any scientific field that involves software or data analysis has already been impacted a lot. (We use LLMs a ton for coding here at Rowan, as I’m sure do all other software-adjacent scientific enterprises.)
Machine-learning models are a godsend for complex simulation problems across lots of different fields: climate modeling, fluid dynamics, systems biology, chemistry & materials science, and so forth. These models too are already seeing production use across lots of domains; to date, most of our work at Rowan has been focused in this area.
Literature review and information retrieval is well-suited for LLMs: FutureHouse and others have done good work here, and it’s likely that we’ll see many more improvements in this domain.
And there are myriad uses for computer vision and robotics in lab automation and monitoring, many of which are already being explored.
All of the above feel inevitable to me—even if all fundamental AI progress halted, it is virtually inevitable that we would see significant and impactful progress in each of these areas for years to come. Here I instead want to focus on the more speculative idea of “AI scientists,” or agentic AI systems capable of some independent and autonomous scientific exploration. After having a lot of conversations about “AI scientists” recently from people with very different backgrounds, I’ve developed some opinions on the field.
Note: while it’s standard practice to talk about AI models in personal terms, anthropomorphizing AI systems can allow writers to sneak in certain metaphysical assumptions. I suspect that any particular stance I take here will alienate some fraction of my audience, so I’m going to put the term “AI scientist” in quotes for the rest of this post to make it clear that I’m intentionally not taking a stance on the underlying metaphysics here. You can mentally replace “AI scientist” with “complex probabilistic scientific reasoning tool,” if you prefer, and it won’t impact any of my claims.
I’m also taking a permissive view of what it means to be a scientist here. To some people, being a scientist means that you’re independently capable of following the scientific method in pursuit of underlying curiosity-driven research. I don’t think this idealistic vision practically describes the bulk of what “science” actually looks like today, as I’ve written about before, and I think lots of people who have “Scientist” in their job titles are instead just doing regular optimization- or search-based work in technical areas. If calling these occupations “science” offends you or you think there’s additional metaphysical baggage associated with being a “scientist,” you’re welcome to mentally replace “AI scientist” with “AI research assistant,” “AI lab technician,” or “AI contract researcher” and it also won’t materially impact this post.
With those caveats out of the way, here’s seven ideas which I currently believe are true about “AI scientists.”
1. “AI scientists” are capable of meaningfully assisting scientific work.
Early drafts of this post didn’t include this point, because after spending time in Silicon Valley I thought the potential of “AI scientists” was obvious enough to be axiomatic. But early readers’ responses reminded me that the East Coast is full of decels that different groups have very different intuitions about AI, so I think it’s worth dwelling on this point a little bit.
Some amount of skepticism about deploying “AI scientists” on real problems is warranted, I think. At a high level, we can partition scientific work into two categories:
Deductive work, in which we perform some deterministic sequence of steps to go from input data to conclusions. This could look like performing a statistical analysis, retrieving data from the environment, or running a simulation.
Inductive work, in which we use creativity or intuition to arrive at hypotheses, experimental designs, or potential conclusions.
One objection to “AI scientists” might go like this: current models like LLMs are unreliable, so we don’t want to rely on them for deductive work. If I want to do deductive work, I’d rather use software with “crystallized intelligence” that has hard-coded verifiable ways to get the correct answer; I don’t want my LLM to make up a new way to run ANOVA every time, for instance. LLMs might be useful for vibe-coding a downstream deductive workflow or for conducting exploratory data analysis, but the best solution for any deductive problem will probably not be an LLM.
But also, we hardly want to rely on LLMs for inductive work, since we can’t verify that their conclusions will be correct. Counting on LLMs to robustly get the right conclusions from data in a production setting feels like a dubious proposition—maybe the LLM can propose some conclusions from a paper or help scientists perform a literature search, but taking the human all the way out of the loop seems dangerous. So if the LLMs can’t do induction and they can’t do deduction, what’s the point?
I think this objection makes a lot of sense, but I think there’s still a role for AI models today in science. Many scientific problems combine some amount of open-ended creativity with subsequent data-driven testing—consider, for instance, the drug- and materials-discovery workflows I outlined in my previous essay about how “workflows are the new models.” Hypothesis creation requires creativity, but testing hypotheses requires much less creativity and provides an objective way to test the ideas. (There’s a good analogy to NP-complete problems in computer science: scientific ideas are often difficult to generate but simple to verify.)
Concretely, then, I think there’s a lot of ways in which even hallucination-prone “AI scientists” can meaningfully accelerate science. We can imagine creating task- and domain-specific agentic workflows in which models propose new candidates on the basis of literature and previous data and then test these models using deterministic means. (This is basically how a lot of human scientific projects work anyhow.) Even if “AI scientists” are 5x or 10x worse than humans at proposing new candidates, this can still be very useful so long as the cost of trying new ideas is relatively low: I would rather have an “AI scientist” run overnight and virtually screen thousands of potential catalysts than have to manually design a dozen catalysts myself.
(All of these considerations change if the cost of trying new ideas becomes very high, which is why questions about lab automation become so important to ambitious “AI scientist” efforts. More on this later in the essay.)
Viewed through this framework, “AI scientists” are virtually guaranteed to be useful so long as they’re able to generate useful hypotheses in complex regimes with more-than-zero accuracy. While this might not have been true a few models ago, there’s good evidence emerging that it’s definitely true now: I liked this paper from Nicholas Runcie, but there are examples from all over the sciences showing that modern LLMs are actually pretty decent at scientific reasoning and getting better. Which brings us to our next point…
2. “AI scientists” are here, even if you don’t want to call them that.
A few years ago, “AI scientists” and “autonomous labs” were considered highly speculative ideas outside certain circles. Now, we’ve seen a massive amount of capital deployed towards building what are essentially “AI scientists”: Lila Sciences and Periodic Labs have together raised almost a billion dollars in venture funding, while a host of other companies have raised smaller-but-still-substantial rounds in service of similar goals: Potato, Cusp, Radical AI, and Orbital Materials all come to mind.
Frontier research labs are also working towards this goal: Microsoft recently announced the Microsoft Discovery platform, while OpenAI has been scaling out their scientific team. (There are also non-profits like FutureHouse working towards building AI scientists.) All of this activity speaks to a strong revealed preference that short-term progress in this field is very likely (although, of course, these preferences may be wrong). If you’re skeptical of these forward-looking signs, though, there’s a lot of agentic science that’s already happening right now in the real world.
A few weeks ago, Benchling (AFAIK the largest pre-clinical life-science software company) released Benchling AI, an agentic scientific tool that can independently search through company data, conduct analysis, and run simulations. While Benchling isn’t explicitly framing this as an “AI scientist,” that’s essentially what this is—and the fact that a large software company feels confident enough to deploy this to production across hundreds of biotech and pharma companies should be a strong sign that “AI scientists” are here to stay.
There are a lot of reasonable criticisms one can make here about branding and venture-funded hype cycles, what constitutes independent scientific exploration vs. mere pattern matching, and so on & so forth. And it’s possible that we won’t see many fundamental advances here—perhaps AI models are reaching some performance ceiling and will be capable of only minor tool use and problem solving, not the loftier visions of frontier labs. But even skeptics will find it virtually impossible to escape the conclusion that AI systems that are capable of non-trivial independent and autonomous scientific exploration are already being deployed towards real use cases, and I think this is unlikely to go away moving forward.
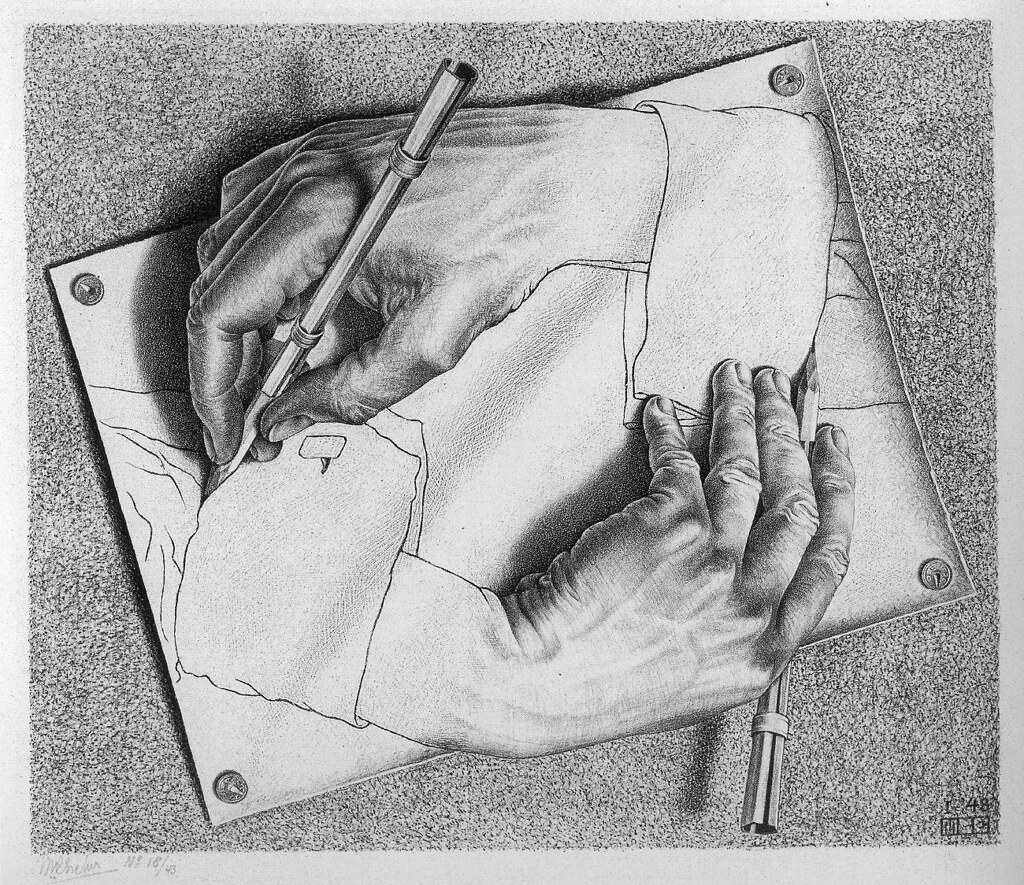
3. Increasing automation will shift the layer of abstraction at which humans work.
Drawing Hands, M. C. Escher (1948)
When I started my undergraduate degree, I recorded NMR spectra manually by inserting a sample into the spectrometer and fiddling with cables, shims, and knobs on the bottom of the machine. By the time I finished my PhD, we had switched over to fully automated NMR systems—you put your sample in a little holder, entered the number of the holder and the experiment that you wanted to be run, and walked away. In theory, this could mean that we didn’t have to spend as much time on our research; in practice, we all just ended up running way more NMR experiments since it was so easy.
This anecdote illustrates an important point: as increasing automation happens, the role of human scientists just smoothly shifts to accommodate higher- and higher-level tasks. One generation’s agent becomes the next generation’s tool. I expect that the advent of “AI scientists” will mean that humans can reposition themselves to work on more and more abstract tasks and ignore a growing amount of the underlying minutiae—the work of scientists will change, but it won’t go away.
This change is not only good but necessary for continued scientific progress. I’ve written before about how data are getting cheaper: across a wide variety of metrics, the cost per data point is falling and the amount of data needed to do cutting-edge science is increasing concomitantly. Viewed from this perspective, “AI scientists” may be the only way that we’re able to continue to cope with the complexity of modern scientific research.
As the scope of research grows ever broader, we will need the leverage that “AI scientists” can give us to continue pursuing ever-more impactful and ambitious scientific projects. With luck, we’ll look back on the days of manually writing input files or programming lab instruments and wonder how we ever got anything done back then. This is doubly true if we consider the leverage afforded by lab automation: automating routine experiments will allow humans to focus on developing new techniques, designing future campaigns, or deeply analyzing their data.
(A closely related idea is that of the “burden of knowledge”—as we learn more and more about the world, it becomes progressively more and more difficult for any one person to learn and maintain all this information. For the unfamiliar, Slate Star Codex has a particularly vivid illustration of this idea. There are several AI-related solutions to this problem: increased compartmentalization and abstraction through high-level tool use helps to loosely couple different domains of knowledge, while improved mechanisms for literature search and digestion make it easier to learn and retrieve necessary scientific knowledge.)
4. Much important scientific knowledge is tacit or illegible, which will make full automation of science difficult.
Moses Smashing the Tablets of the Law, Gustave Doré (1866)
In Seeing Like A State, James Scott contrasts technical knowledge (techne) with what he calls metis (from Greek μητις), or practical knowledge. One of the unique characteristics of metis is that it’s almost impossible to translate into “book knowledge.” I’ll quote directly from Scott here (pp. 313 & 316):
Metis represents a wide array of practical skills and acquired intelligence in responding to a constantly changing natural and human environment.… Metis resists simplification into deductive principles which can successfully be transmitted through book learning, because the environments in which it is exercised are so complex and non-repeatable that formal procedures of rational decision making are impossible to apply.
My contention is that there’s a lot of metis in science, particularly in experimental science. More than almost any other field, science still adheres to a master–apprentice model of learning wherein practitioners build up skills over years of practice and careful study. While some of the knowledge acquired in a PhD is certainly techne, there’s a lot that’s metis as well. Ask any experimental scientist and they’ll tell you about the tricks, techniques, and troubleshooting that were key to any published project (and which almost never make it into the paper).
For non-scientists, the story of BlogSyn may help to illustrate what I mean. BlogSyn was a project in which professional organic chemists attempted to reproduce published reactions based only on the procedure actually written in the literature. On paper, this seems like it should work: one expert scientist reads a peer-reviewed publication with a detailed experimental procedure and reproduces a randomly chosen result. In two out of three cases, however, the authors were unable to get the reaction to work as reported without consulting the original authors. (The saga with Phil Baran lasted about a month and became a bit acrimonious: here’s part 1 and part 2.)
The moral of this story isn’t that the original authors were negligent, I think. Rather, it turns out that it’s really hard to actually convey all of the experience of laboratory science through the written word, in keeping with Scott’s points about metis. A genius scientist who’d read every research paper but never set foot in a lab would not be able to immediately become an effective researcher, but this is basically what we expect from lofty visions of “AI scientists.”
Accelerationist lab-automation advocates might argue that metis is basically “cope”: in other words, that technological improvements will obviate the need for fuzzy human skills just like mechanical looms and sewing machines removed the need for textile craftsmanship. There’s some truth to this: improvements in automation can certainly make it easier to run experiments. But robust automatable protocols always lag after the initial flexible period of exploration. One first discovers the target by any means necessary and only later finds a way to make the procedure robust and reliable. “AI scientists” will need to be able to handle the ambiguity and complexity of novel experiments to make the biggest discoveries, and this will be hard.
Humans can help, and I think that keeping humans somewhere in the loop will go a long way towards addressing these issues. The vast majority of AI-based scientific successes to date have implicitly relied on some sort of metis somewhere in the stack: if you’re training an AI-based reaction-prediction model on high-throughput data collected autonomously, the original reaction was still developed through the hard-earned intuition of human scientists. In fact, one can imagine in analogy to Amdahl’s Law that automation would vastly increase the returns to metis rather than eliminating it.
Given all these considerations, I expect that building fully self-driving labs will be much harder than most people think. The human tradition of scientific knowledge is powerful and ought not to be lightly discarded. I don’t think it’s a coincidence that the areas where the biggest “AI scientist” successes have happened to date—math, CS, and computational science—are substantially more textually legible than experimental science, and I think forecasting success from these fields into self-driving labs is likely to prove misleading.
(Issues of metis aren’t confined to experimental science—the “scientific taste” about certain ideas that researchers develop is also a form of metis that at present seems difficult to convey to LLMs. But I think it’s easier to imagine solving these issues than the corresponding experimental problems.)
5. Integrating deterministic simulation tools with more flexible agents will be useful.
In a previous post on this blog, I wrote about using ChatGPT to play GeoGuessr—there, I found that o3 would quietly solve complicated trigonometric equations under the hood to predict latitude using Python. o3 is a pretty smart model, and it’s possible that it could do the math itself just by thinking about it, but instead it uses a calculator to do quantitative reasoning (the same way that I would). More generally, LLMs seem to mirror a lot of human behavior in how they interact with data: they’re great at reading and remembering facts, but they’re not natively able to do complex high-dimensional reasoning problems just by “thinking about them” really hard.
Human scientists solve this problem by using tools. If I want to figure out the correlation coefficient for a given linear fit or the barrier height for a reaction, I don’t try to solve it in my head—instead, I use some sort of task-specific external tool, get an answer, and then think about the answer. The conclusion here is obvious: if we want “AI scientists” to be any good, we need to give them the same tools that we’d give human scientists.
Many people are surprised by this claim, thinking instead that superintelligent “AI scientists” will automatically rebuild the entire ecosystem of scientific tools from scratch. Having tried to vibe-code a fair number of scientific tools myself, I’m not optimistic. We don’t ask coding agents to write their own databases or web servers from scratch, and we shouldn’t ask “AI scientists” to write their own DFT code or MD engines from scratch either.
More abstractly, there’s an important and natural partition between deterministic simulation tools and flexible agentic systems. Deterministic simulation tools have very different properties than LLMs—there’s almost always a “right answer,” meaning that the tools can be carefully benchmarked and tested before being embedded within a larger agentic system. Since science is complicated, this ability to partition responsibility and conduct component-level testing will be necessary for building robust systems.
Deterministic simulation tools also require fixed input and output data: they’re not able to handle the messy semi-structured data typical of real-world scientific problems, instead relying on the end user to convert this into a well-structured simulation task. Combining these tools with an LLM makes it possible to ask flexible scientific questions and get useful answers without being a simulation expert; the LLM can deploy the tools and figure out what to make of the outputs, reducing the work that the end scientist has to do.
6. Building tools for AIs will be a lot like building tools for humans.
Rowan, the company I co-founded in 2023, is an applied research company that focuses on building a design and simulation platform for drug discovery and materials science. We work to make it possible to use computation to accelerate real-world discovery problems—so we develop, benchmark, and deploy computational tools to scientific teams with a focus on pragmatism and real-world impact.
When we started Rowan, we didn’t think much about “AI scientists”—I assumed that the end user of our platform would always be a human, and that building excellent ML-powered tools would be a way to “give scientists superpowers” and dramatically increase researcher productivity and the quality of their science. I still think this is true, and (as discussed above) I doubt that we’re going to get rid of human-in-the-loop science anytime soon.
But sometime over the last few months, I’ve realized that we’re building tools just as much for “AI scientists” as we are for human scientists. This follows naturally from the above conclusions: “AI scientists” are here, they’re going to be extremely important, and they’re going to need tools. Even more concretely, I expect that five years from now more calculations will be run on Rowan by “AI scientists” than human scientists. To be clear, I think that these “AI scientists” will still be piloted at some level by human scientists! But the object-level task of running actual calculations will be more often than not done by the “AI scientists,” or at least that’s the prediction.
How does “building for the ‘AI scientists’” differ from building for humans? Strangely, I don’t think the task is that different. Obviously, there are some trivial interface-related considerations: API construction matters more for “AI scientists,” visual display matters less, and so on & so forth. But at a core level, the task of the tool-builder is simple—to “cut reality at its joints” (following Plato), to find the natural information bottlenecks that create parsimonious and composable ways to model complex systems. Logical divisions between tools are intrinsic to the scientific field under study and do not depend on the end user.
This means that a good toolkit for humans will also be a good toolkit for “AI scientists,” and that we can practice building tools on humans. In some sense, one can see all of what we’re doing at Rowan as practice: we’re validating our scientific toolkit on thousands of human scientists to make sure it’s robust and effective before we hand it off to the “AI scientists.”
7. The future of science will look like some degree of recursive AI-mediated abstraction.
St. Paul Preaching to the Thessalonians, Gustave Doré (1866)
If logical divisions between tools are indeed intrinsic to scientific fields, then we should also expect the AI-driven process of science to be intelligible to humans. We can imagine a vision of scientific automation that ascends through progressively higher layers of abstraction. Prediction is hard, especially about the future, but I’ll take a stab at what this might look like specifically for chemistry.
At low levels, we have deterministic simulation tools powered by physics or ML working to predict the outcome and properties of specific physical states. This requires very little imagination: Rowan’s current product (and many others) act like this, and computational modeling and simulation tools are already deployed in virtually every modern drug- and materials-design company.
Above that, we can imagine “AI scientists” managing well-defined multi-parameter optimization campaigns. These agents can work to combine or orchestrate the underlying simulation tasks in pursuit of a well-defined goal, like a given target–product profile, while generating new candidates based on scientific intuition, previous data, and potentially human input. Importantly, the success or failure of these agents can objectively be assessed by tracking how various metrics change over time, making it easy for humans to supervise and verify the correctness of the results. Demos of agents like this are already here, but I think we’ll start to see these being improved and used more widely within the next few years.
Other “AI scientist” phenotypes could also be imagined—while progress in lab automation is difficult to forecast, it’s not hard to hope for a future in which a growing amount of routine lab work could be automated and overseen by “AI scientists” working to debug synthetic routes and verify compound identity. As discussed above, my timelines for this are considerably gloomier than for simulation-only agents owing to the metis issue, but it’s worth noting that even focused partial solutions here would be quite helpful. This “experimental AI scientist” would naturally complement the “computational AI scientist” described in the previous paragraph, even if considerable human guidance and supervision is needed.
A third category of low-level “AI scientist” is the “AI research assistant” that conducts data analysis and reads the literature. This is basically an enhancement of Deep Research, and I think some form of this is already available and will be quite useful within the next few years.
It’s easy to imagine a human controlling all three of the above tools, just like an experienced manager can deploy an army of lab techs and contracts towards a specific target. But why not ascend to an even higher layer of abstraction? We can imagine “AI project managers” that coordinate computational screening, experimentation, and literature search agents towards a specific high-level goal. These agents would be in charge of efficiently allocating resources between exploration and exploration on the basis of the scientific literature, simulated results, and previous experimental data—again, they could easily be steered by humans to improve their strategy or override prioritization.
This last layer of abstraction probably only makes sense if (1) the low-level abstractions become sufficiently robust and either (2) the cost of experimentation falls low enough that human supervision becomes a realistic bottleneck or (3) the underlying models become smart enough that they’re better at managing programs than humans are. Different people have very different intuitions about these questions, and I’m not going to try and solve them here—it’s possible that supervision at this level remains human forever, or it’s possible that GPT-6 is capable enough that you’d rather let the AI models manage day-to-day operations than a person. I would be surprised if “AI scientists” were operating at this level within the next five years, but I wouldn’t rule it out in the long term.
The overall vision might sound a little bit like science fiction, and at present it remains science fiction. But I like this recursively abstracted form of scientific futurism because it’s ambitious while preserving important properties like legibility, interpretability, and auditability. There are also tangible short-term goals associated with this vision: individual components can be tested and optimized independently and, over time, integrated into increasingly capable systems. We don’t need to wait around for GPT-6 to summon scientific breakthroughs “from the vasty deeps”—the early steps we take down this road will be useful even if true scientific superintelligence never arrives.
In the course of writing this piece, I realized that without trying I’d basically recapitulated Alice Maz’s vision for “AI-mediated human-interpretable abstracted democracy” articulated in her piece on governance ideology. Quoting Hieronym’s To The Stars, Maz suggests that an AI-mediated government should follow the procedure of human government where possible “so that interested citizens can always observe a process they understand rather than a set of uninterpretable utility‐optimization problems.” I think this is a good vision for science and the future of scientists, and it’s one I plan to work towards.
* * *
Just to make the implicit a bit more explicit: here at Rowan, we are very interested in working with companies building “AI scientists.” If you are working in drug discovery, materials science, or just general “AI for science” capabilities and you want to work with our team to deploy human-validated scientific tools on important problems, please reach out! We are already working with teams in this space and would love to meet you.
Thanks to many folks whom I cannot name for helpful discussions on these topics, and to Ari Wagen, Charles Yang, Spencer Schneider, and Taylor Wagen for editing drafts of this piece.
I don’t write about my non-working life much on the Internet; my online presence has been pretty closely tied to Rowan and I try to adhere to some level of what Mary Harrington calls “digital modesty” regarding my family. Still, some basic demographics are helpful for context.
I have two kids (aged 2 and 4) and one more due in December. My children have many and varied interests: they like playing GeoGuessr with me, they like making forts, they like pretending to serve food, they like playing with Lego, and—most importantly for this post—they like coloring pictures.
Dad–daughter coloring time, ft. her toothbrush which she brought over for no apparent reason.
I find myself printing out a lot of coloring pages these days, and I’ve been generally disappointed by the quality of coloring pages on Google Images. My son often has very specific requests (e.g. “a picture of Starscream fighting”) and it’s difficult to find a coloring page that matches his vision. I have similar problems: I like coloring historical maps because it helps me understand history a bit better, but it’s hard to find good coloring pages of historical maps.
This problem has bothered me for a while. I tried using ChatGPT for this when 4o started being able to generate images, but the results were terrible. Here’s what ChatGPT thought a map of medieval Europe in 1000 AD should look like, for instance:
Points for making modern-day Romania part of the Eastern Roman empire (Ρωμανία), I suppose, but this is unusably bad.
After giving up for a few months, I revisited this problem again recently. My goal this time around was to vibe-code a way to convert any image into a coloring page. (If the idea of “vibe coding” is unfamiliar to you, refer to Andrej Karpathy’s post on X.) I gave the prompt to both GPT 5 and Claude 4.1 Opus: while GPT 5 got confused and started creating epicyclically complex Numpy code, Claude 4.1 gave me a pretty clean solution using OpenCV.
The full code is on Github. Here’s Claude’s summary of its approach, which I confess I don’t fully understand (in the spirit of vibe coding):
This code converts colored images into black-and-white line drawings using multiple computer vision techniques tailored to different image types. The implementation provides three main extraction methods: character-based, color boundary-based, and adaptive threshold-based processing.
The character extraction method combines three edge detection approaches. It first applies CLAHE (Contrast Limited Adaptive Histogram Equalization) with a clip limit of 3.0 and 8x8 tile grid to enhance local contrast. It then uses adaptive thresholding with a 9x9 Gaussian window, Canny edge detection (50-150 thresholds) on a Gaussian-blurred image, and Laplacian operators with a threshold of 30. These outputs are combined using bitwise AND operations to preserve edges while reducing noise. The pipeline includes connected component analysis to remove regions smaller than 25 pixels and morphological closing with a 2x2 kernel to fill gaps.
The color boundary method operates in two parallel paths. The first path converts the image to LAB color space after bilateral filtering (d=5, sigmaColor=50, sigmaSpace=50) and runs Canny edge detection (40-80 thresholds) on each channel independently. The second path processes the grayscale image with a sharpening kernel, applies higher-threshold Canny detection (100-250), adaptive thresholding with a 7x7 window, and morphological gradient operations. Text features are preserved by combining these methods and removing components smaller than 4 pixels. Both paths merge via bitwise OR operations.
All methods support adjustable line thickness through erosion or dilation with 3x3 cross-shaped kernels. The adaptive threshold method uses CLAHE preprocessing (clip limit 2.0) followed by 11x11 Gaussian adaptive thresholding combined with Canny edges (30-100 thresholds). Final outputs undergo morphological opening with a 2x2 kernel for noise reduction.
Here’s a few examples. This is a picture of Optimus Prime from Google Images and the corresponding coloring page (for my son):
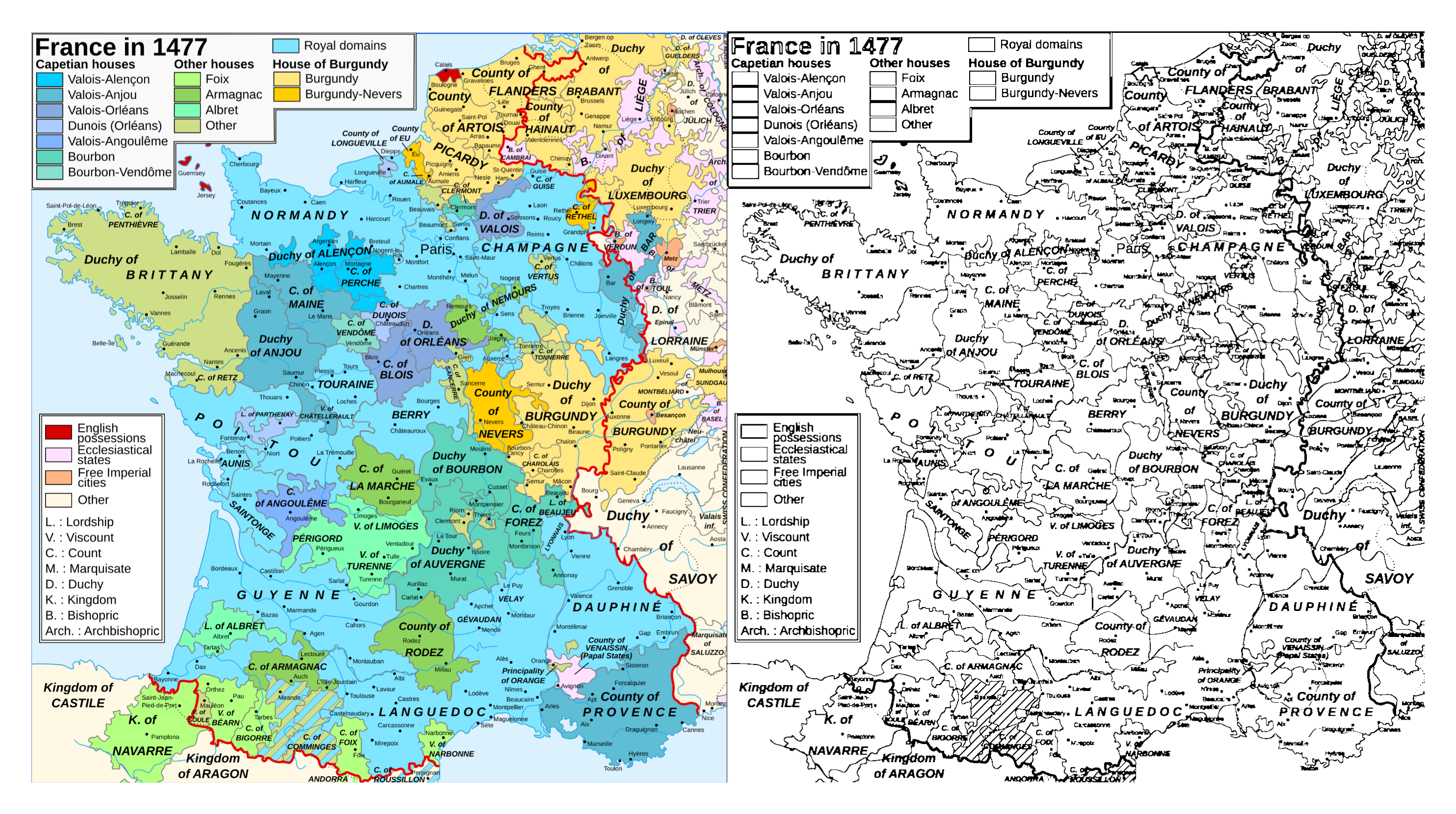
This is a map of medieval French duchies and counties and the corresponding coloring page (for me):
Neither of these are perfect! In both cases, the important boundaries are a bit lost in the details: Optimus’s outline is a bit unclear in some areas, and it’s tough to tell e.g. where Brittany’s boundaries are without the colored image as a reference. (The text also gets a little damaged in the map.) I’m sure someone who’s good at computer vision could do a better job here—using a tool like Dino v3 or Segment Anything could probably help, as could understanding what the above code is actually doing.
Still, this is good enough for routine usage and certainly better than the maps I could find floating around on the internet. I’m pretty happy with what a small amount of vibe-coding can accomplish, and I thought I’d share this anecdote in case other parents out there are looking for bespoke coloring pages.
August 16, 2025The Astronomer, Johannes Vermeer (c. 1668)
I’ve been sitting on this post for well over a year. This is the sort of thing I might consider turning into a proper review if I had more time—but I’m quite busy with other tasks, I don’t feel like this is quite comprehensive or impersonal enough to be a great review, and I’ve become pretty ambivalent about mainstream scientific publishing anyway.
Instead, I’m publishing this instead as a longform blog post on the state of NNP architectures, even though I recognize this may be interesting only to a small subset of my followers. Enjoy!
Atom-level simulation of molecules and materials has traditionally been limited by the immense complexity of quantum chemistry. Quantum-mechanics-based methods like density-functional theory struggle to scale to the timescales or system sizes required for many important applications, while simple approximations like molecular mechanics aren’t accurate enough to provide reliable models of many real-world systems. Despite decades of continual advances in computing hardware, algorithms, and theoretical chemistry, the fundamental tradeoff between speed and accuracy still limits what is possible for simulations of chemical systems.
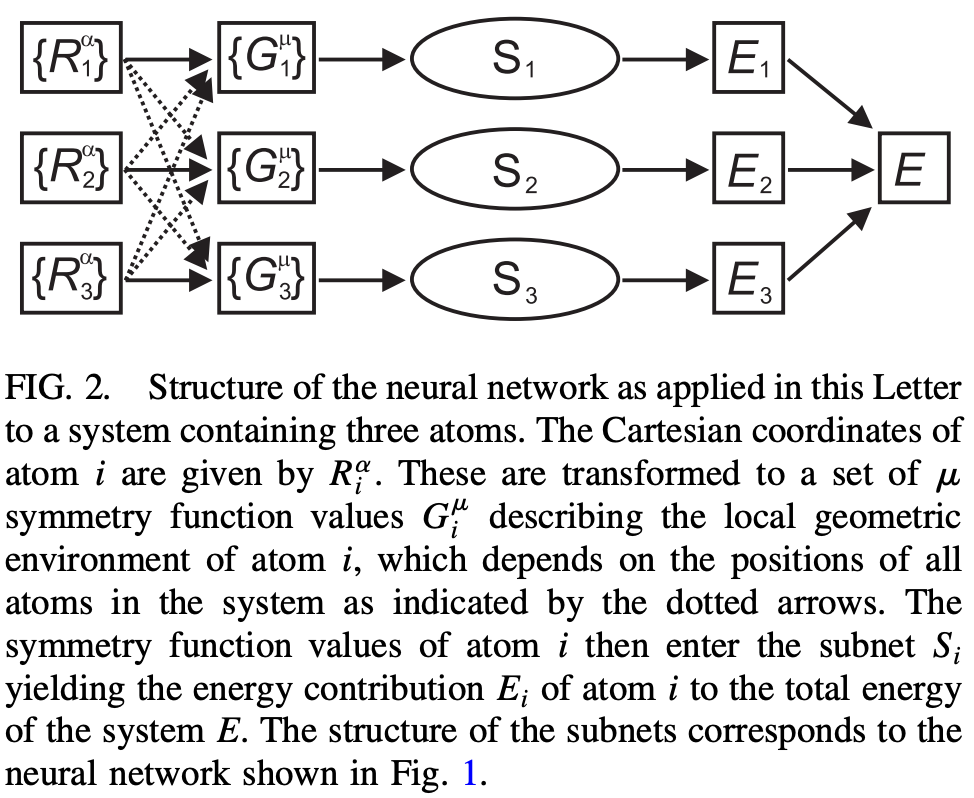
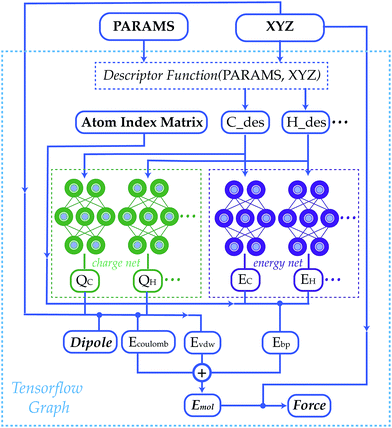
Over the past two decades, machine learning has become an appealing alternative to the above dichotomy. In theory, a sufficiently advanced neural network potential (NNP) trained on high-level quantum chemical simulations can learn to reproduce the energy of a system to arbitrary precision, and once trained can reproduce the potential-energy surface (PES) many orders of magnitude faster than quantum chemistry, thus enabling simulations of unprecedented speed and accuracy. (If you’ve never heard of an NNP, Ari’s guide might be helpful.)
In practice, certain challenges arise in training an NNP to reproduce the PES calculated by quantum chemistry. Here’s what Behler and Parinello say in their landmark 2007 paper:
[The basic architecture of neural networks] has several disadvantages that hinder its application to high-dimensional PESs. Since all weights are generally different, the order in which the coordinates of a configuration are fed into the NN [neural network] is not arbitrary, and interchanging the coordinates of two atoms will change the total energy even if the two atoms are of the same type. Another limitation related to the fixed structure of the network is the fact that a NN optimized for a certain number of degrees of freedom, i.e., number of atoms, cannot be used to predict energies for a different system size, since the optimized weights are valid only for a fixed number of input nodes.
To avoid these problems, Behler and Parinello eschew directly training on the full 3N coordinates of each system, and instead learn a “short-range” potential about each atom that depends only on an atom’s neighbors within a given cutoff radius (in their work, 6 Å). Every atom of a given element has the same local potential, thus ensuring that energy is invariant with respect to permutation and making the potential more scalable and easier to learn.
This overall approach has served as the groundwork for most subsequent NNPs: although the exact form of the function varies, most NNPs basically work by learning local molecular representations within a given cutoff distance and extrapolating to larger systems. Today, most NNPs follow the “graph neural network” (GNN) paradigm, and the vast majority also incorporate some form of message passing (for more details, see this excellent review from Duval and co-workers).
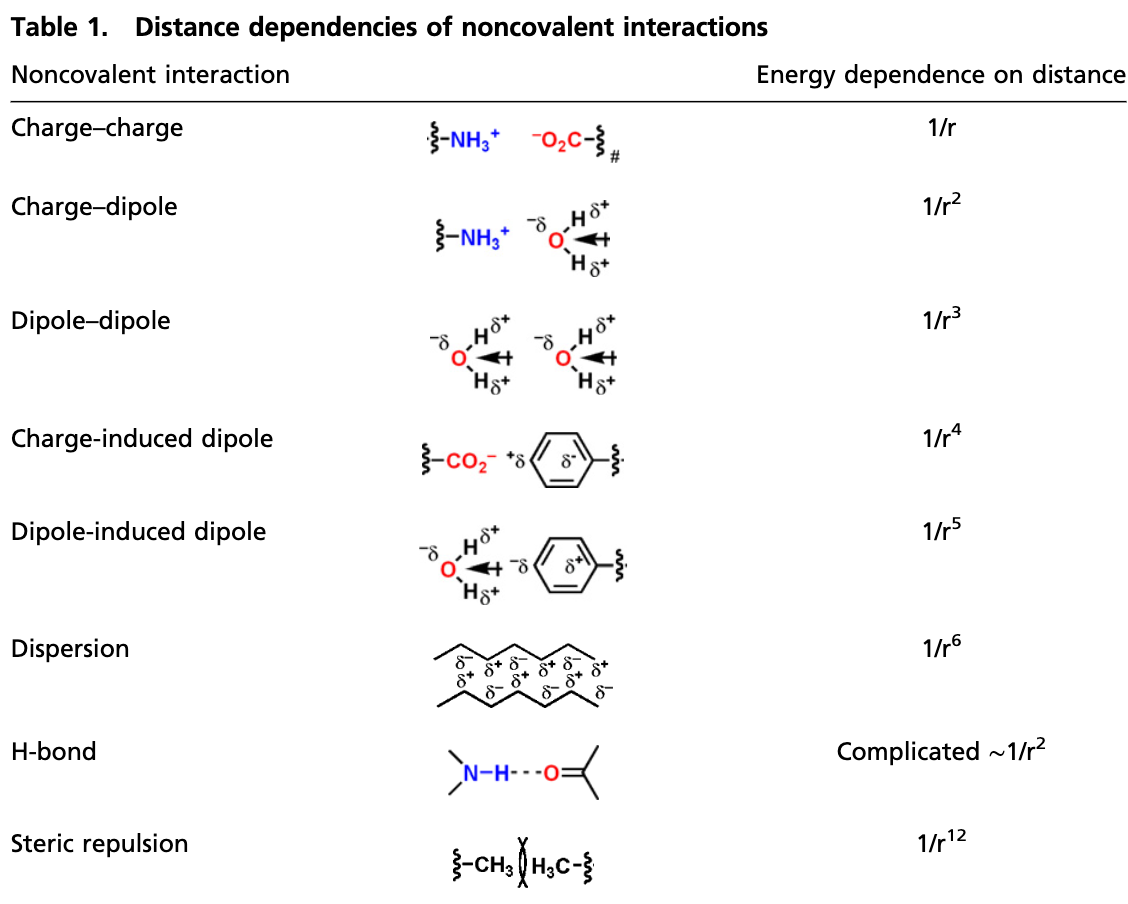
There are intuitive and theoretical reasons why this is a reasonable assumption to make: “locality is a central simplifying concept in chemical matter” (Chan), “local cutoff is a powerful inductive bias for modeling intermolecular interactions” (Duval), and the vast majority of chemical phenomena are highly local. But a strict assumption of locality can cause problems. Different intermolecular interactions have different long-range behavior, and some interactions drop off only slowly with increasing distance. See, for instance, this chart from Knowles and Jacobsen:
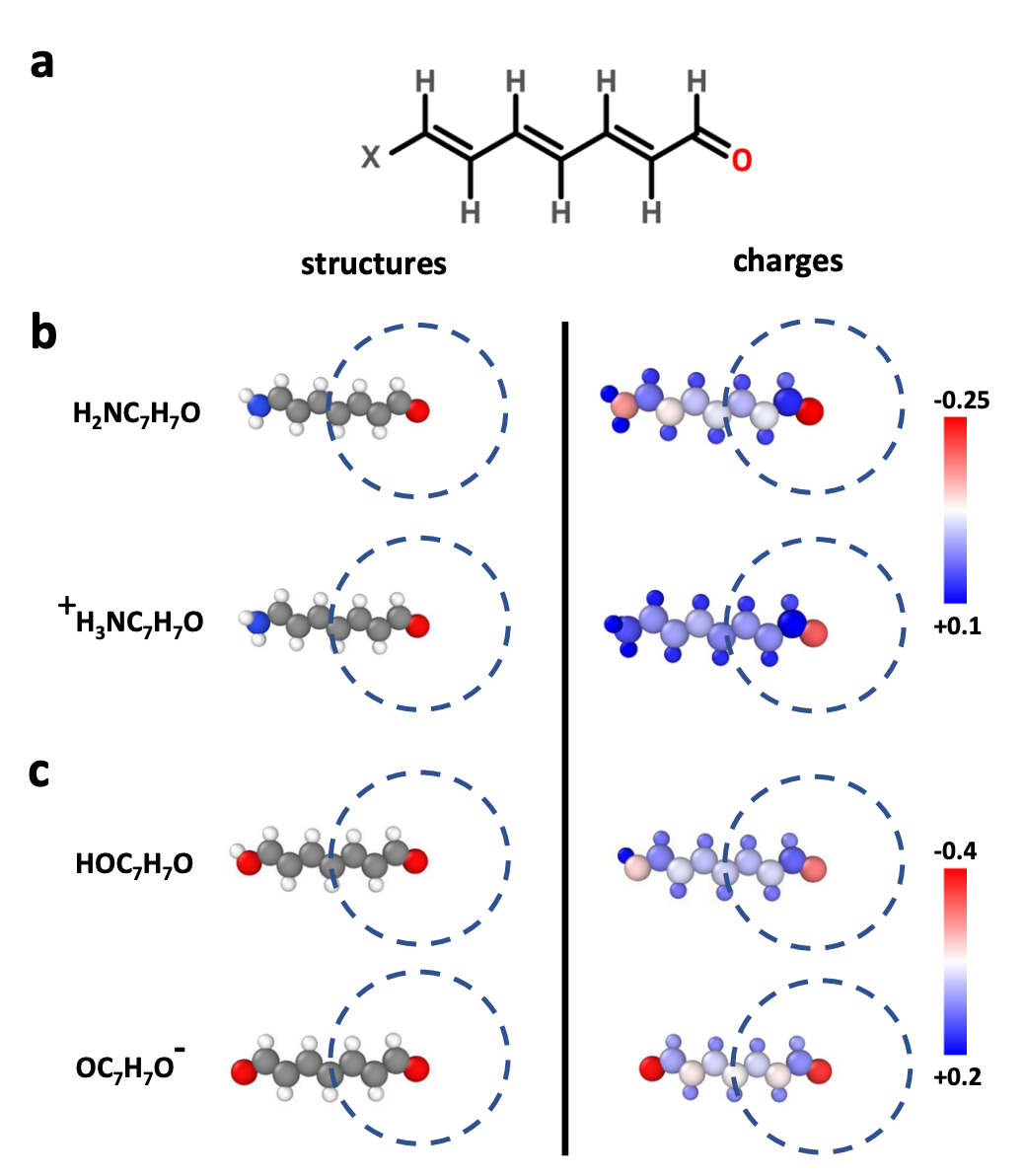
As the above chart shows, interactions involving charged species can remain significant even at long distances. For example, a positive charge and a negative charge 15 Å apart in the gas phase exert a force of 1.47 kcal/mol/Å on each other; for those outside the field, that’s quite large. (In the condensed phase, this is reduced by a constant factor corresponding to the dielectric constant ε of the medium: for water, ε ≈ 78.)
This creates problems for NNPs, as naïve application of a 6 Å cutoff scheme would predict no force between the above charges. While NNPs can still perform well for systems without substantial long-range forces without addressing this problem, lots of important biomolecules and materials contain charged or ionic species—making it a virtual certainty that NNPs will have to figure out these issues sooner or later.
Almost everyone that I’ve talked to agrees that this problem is important, but there’s very little agreement on what the right approach forward is. I’ve spent the past few years talking to lots of researchers in this area about this question: while there are literally hundreds of papers on this topic, I think most approaches fall into one of three categories:
Scale up existing local GNN approaches. Some approaches simply solve the long-range-force problem by making the NNPs larger—larger cutoff radii, more layers, and more data.
Add explicit physics. Other approaches borrow from molecular mechanics and add explicit physics-based models of long-range forces.
Use non-local neural networks. Still other approaches relax the locality of a pure GNN-based approach and train NNPs that can pass information over longer distances.
In this post, I’ll try to give a brief overview of all three paradigms. I’ll discuss how each approach works, point to evidence suggesting where it might or might not work, and discuss a select case study for each approach. This topic remains hotly debated in the NNP community, and I’m certainly not going to solve anything here. My hope is that this post instead can help to organize readers’ thoughts and, like any good review, help to organize the unstructured primal chaos of the underlying literature.
(There are literally hundreds of papers in this area, and while I’ve tried to cover a lot of ground, it’s a virtual certainty that I haven’t mentioned an important or influential paper. Please don’t take any omission as an intentional slight!)
Category 1 - Scaling Local GNN Approaches
Our first category is NNPs which don’t do anything special for long-range forces at all. This approach is often unfairly pilloried in the literature. Most papers advocating for explicit handling of long-range forces pretend that the alternative is simply discarding all forces beyond the graph cutoff: for instance, a recent review claimed that “interactions between particles more than 5 or 10 angstroms apart are all masked out” in short-range NNPs.
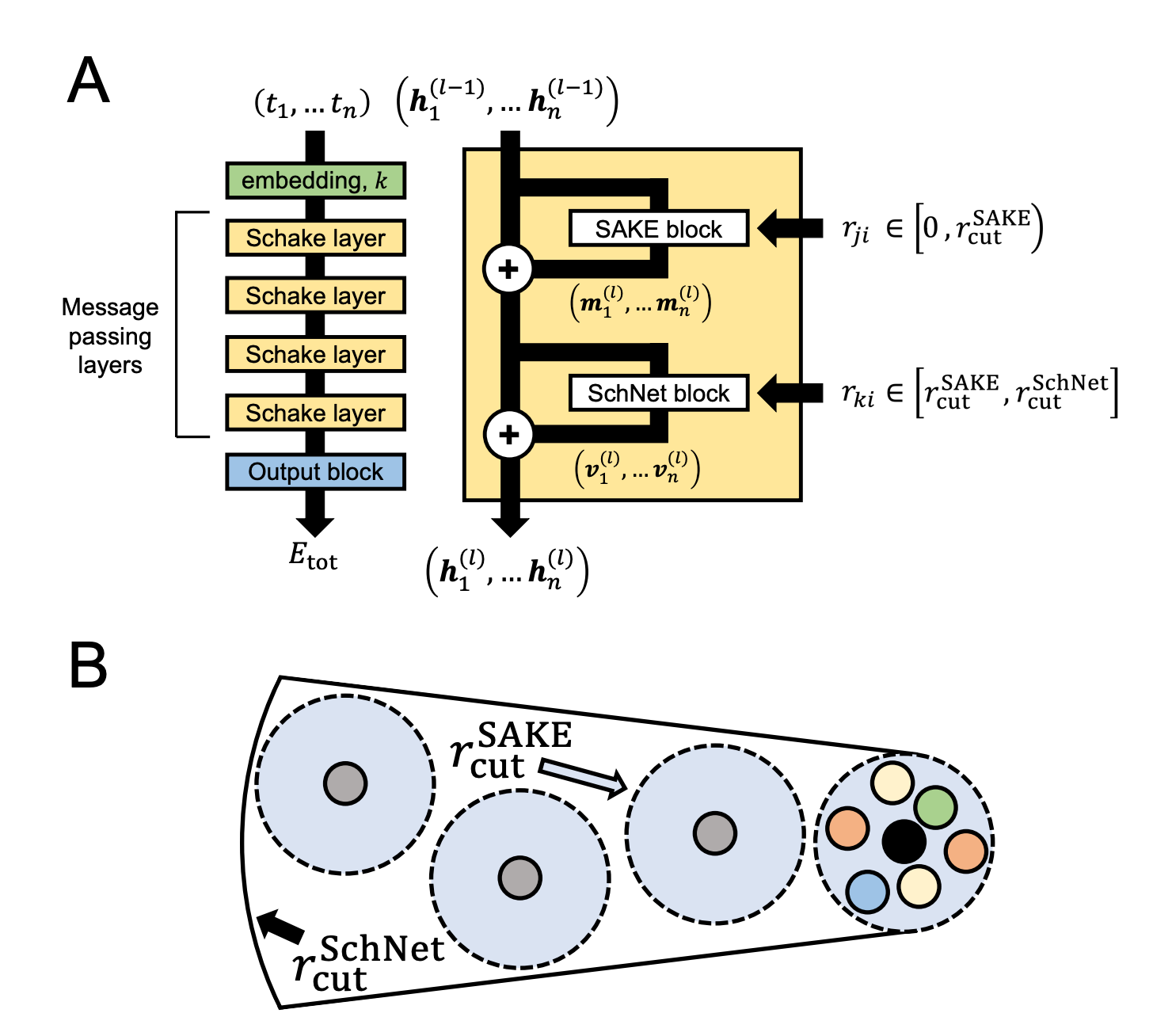
This doesn’t describe modern NNPs at all. Almost all NNPs today use some variant of the message-passing architecture (Gilmer), which dramatically expands the effective cutoff of the model. Each round of message passing lets an atom exchange information with neighbors that are farther away, so a model with a graph cutoff radius of “5 Å” might actually have an effective cutoff of 20–30 Å, which is much more reasonable. It’s easy to find cases in which a force cutoff of 5 Å leads to pathological effects; it’s much harder to find cases in which a force cutoff of 20 Å leads to such effects.
Naïvely, one can calculate the effective cutoff radius as the product of the graph cutoff radius and the number of message-passing steps. Here’s how this math works for the recent eSEN-OMol25 models:
eSEN-OMol25-sm has a cutoff radius of 6 Å and 4 layers for an effective cutoff radius of 24 Å.
eSEN-OMol25-md has a cutoff radius of 6 Å and 10 layers for an effective cutoff radius of 60 Å.
eSEN-OMol25-lg has a cutoff radius of 12 Å and 16 layers for an effective cutoff radius of 192 Å (!).
Since most discussions of long-range forces center around the 10–50 Å range, one might think that the larger eSEN models are easily able to handle long-range forces and this whole issue should be moot.
In practice, though, long-range communication in message-passing GNNs is fragile. The influence of distant features decays quickly because of “oversquashing” (the fixed size of messages compresses information that travels over multiple edges) and “oversmoothing” (repeated aggregation tends to make all node states similar). Furthermore, the gradients of remote features become tiny, so learning the precise functional form of long-range effects is difficult. As a result, even having a theoretical effective cutoff radius of “60 Å” is no guarantee that the model performs correctly over distances of 10 or 15 Å.
How long is long-ranged enough for a good description of properties of interest? The short answer is that it’s not clear, and different studies find different results. There’s good evidence that long-range forces may not be crucial for proper description of many condensed-phase systems. Many bulk systems are able to reorient to screen charges, dramatically attenuating electrostatic interactions over long distances and making it much more reasonable to neglect these interactions. Here’s what Behler’s 2021 review says:
The main reason [why local NNPs are used] is that for many systems, in particular condensed systems, long-range electrostatic energy contributions beyond the cutoff, which cannot be described by the short-range atomic energies in [local NNPs], are effectively screened and thus very small.
There are a growing number of papers reporting excellent performance on bulk- or condensed-phase properties with local GNNs. To name a few:
Meta’s FAIR-chem team recently reported excellent results using the UMA models (vide supra) for crystal-structure prediction, a task where long-range forces have long been thought to be crucial. (See e.g. recent work from Lavo, which argues that “an inability to model long-range interactions is potentially limiting for application to molecular crystals.”)
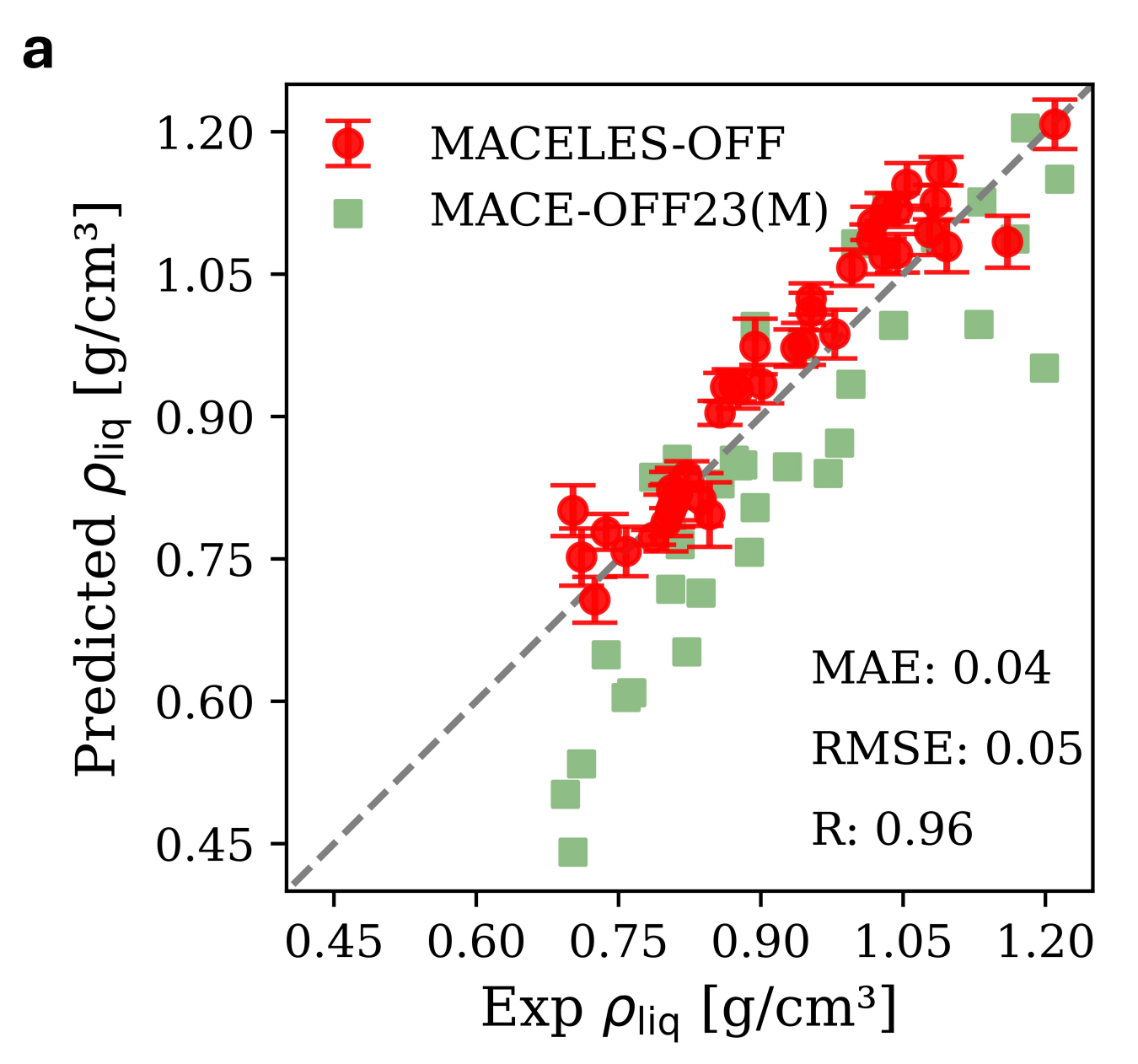
The MACE-OFF23 and MACE-OFF24 models excel at a variety of condensed-phase properties—including peptide dynamics and folding, organic liquid densities, and molecular crystal lattice energy—despite having an effective cutoff radius of only 9–12 Å.
Even strictly local models without message passing can work shockingly well on many systems: Musaelian and co-workers found that equivariant GNNs with a 6 Å cutoff could accurately model both QM9 and solid lithium phosphate electrolytes. (See also their followup on scaling these models.)
Still, there are still plenty of systems where one might imagine that strict assumptions of locality might lead to pathological behavior:
Work by Yue and co-workers has shown that local models with a 6 Å cutoff are able to describe density isotherms and diffusion coefficients of liquid water correctly, but that long-range interactions are required to accurately describe vapor-phase densities.
Piana and co-workers studied protein folding with classical force fields and found that the free energy of folding was relatively insensitive to cutoffs beyond 9 Å, but that the structure of the unfolded state was much more sensitive to the precise cutoff.
Patra and co-workers found that even cutoffs of 25 Å were insufficient to describe lipid bilayers correctly and full particle-mesh-Ewald (PME) treatment was needed. (This work was also done with classical forcefields.)
And it’s trivial to find examples in low-dielectric environments where there are meaningful long-range interactions, like the above example of two point charges 15 Å from each other—although it’s also trivial to add fixes to graph construction such that far-away clusters of atoms are connected with edges.
One common theme here is inhomogeneity—in accordance with previous theoretical work from Janacek, systems with interfaces or anisotropy are more sensitive to long-range forces than their homogenous congeners.
It’s worth noting that none of the above studies were done with state-of-the-art NNPs like MACE-OFF2x or UMA, so it’s possible that these systems don’t actually fail with good local NNPs. There are theoretical reasons why this might be true. Non-polarizable forcefields rely largely on electrostatics to describe non-covalent interactions (and use overpolarized charges), while NNPs can typically describe short- to medium-range NCIs just fine without explicit electrostatics: cf. benchmark results on S22 and S66.
Case Study - The Schake Architecture
An interesting local GNN architecture was recently reported by Justin Airas and Bin Zhang. In the search for scalable implicit-solvent models for proteins, Airas and Zhang found that extremely large cutoff radii (>20 Å) were needed for accurate results, but that conventional equivariant GNNs were way too slow with these large cutoff radii. To address this, the authors use a hybrid two-step approach which combines an accurate short-range “SAKE” layer (5 Å cutoff) with a light-weight long-range “SchNet” layer (25 Å cutoff):
This hybrid “Schake” approach seems to give the best of both worlds, at least for this use case. Schake combines the short-range accuracy of a SAKE-only model with the ability to efficiently retrieve information from longer ranges with SchNet. For large systems, 75–80% of the atom pairs are calculated with SchNet.
I like this approach because—much like a classic multipole expansion—it takes into account the fact that long-range interactions are much simpler and lower-dimensional than short-range interactions, and provides an efficient way to scale purely local approaches while retaining their simplicity.
(Random aside: How do non-physics-based NNPs handle ionic systems? While methods that depend only on atomic coordinates—like ANI, Egret-1, or MACE-OFF2x—can’t tell whether a given system is cationic, neutral, or anionic, it’s pretty easy to add the overall charge and spin as a graph-level feature. Given enough data, one might reasonably expect that an NNP could implicitly learn the atom-centered partial charges and the forces between them. Simeon and co-workers explore this topic in a recent preprint and find that global charge labels suffice to allow TensorNet-based models to describe ionic species with high accuracy over a few different datasets. This is what eSEN-OMol25-small-conserving and UMA do.)
Category 2 - Incorporating Explicit Physics
Previously, I mentioned that Coulombic forces decayed only slowly with increasing distance, making them challenging to learn with traditional local NNP architectures. The astute reader might note that unlike the complex short-range interactions which require extensive data to learn, charge–charge interactions have a well-defined expression and are trivial to compute. If the underlying physics is known, why not just use it? Here’s what a review from Unke and co-workers has to say on this topic:
While local models with sufficiently large cutoffs are able to learn the relevant effects in principle, it may require a disproportionately large amount of data to reach an acceptable level of accuracy for an interaction with a comparably simple functional form.
The solution proposed by these authors is simple: if we already know the exact answer from classical electrostatics, we can add this term to our model and just ∆-learn the missing interactions. This is the approach taken by our second class of NNPs, which employ some form of explicit physics-based long-range forces in addition to machine-learned short-range forces.
There are a variety of ways to accomplish this. Most commonly, partial charges are assigned to each atom, and an extra Coulombic term is added to the energy and force calculation, with the NNP trained to predict the additional “short-range” non-Coulombic force. (Implementations vary in the details: sometimes the Coulombic term is screened out at short distances, sometimes not. The exact choice of loss function also varies here.)
The architecture of TensorMol (Yao et al, 2018), which to my knowledge is the first NNP to incorporate this approach.
Assigning partial charges to each atom is a difficult and non-trivial task. The electron density is a continuous function throughout space, and there’s no “correct” way to discretize it into various points: many different partitioning schemes have been developed, each with advantages and disadvantages (see this legendary Stack Exchange answer).
The simplest scheme is just to take partial charges from forcefields. While this can work, the atomic charges typically used in forcefields are overestimated to account for solvent-induced polarization, which can lead to unphysical results in more accurate NNPs. Additionally, using fixed charges means that changes in bonding cannot be described. Eastman, Pritchard, Chodera, and Markland explored this strategy in the “Nutmeg” NNP—while their model works well for small molecules, it’s incapable of describing reactivity and leads to poor bulk-material performance (though this may reflect dataset limitations and not a failure of the approach).
More commonly, local neural networks like those discussed above are used to predict atom-centered charges that depend on the atomic environment. These networks can be trained against DFT-derived partial charges or to reproduce the overall dipole moment. Sometimes, one network is used to predict both charges and short-range energy; other times, one network is trained to predict charges and a different network is used to predict short-range energy.
This strategy is flexible and capable of describing arbitrary environment-dependent changes—but astute readers may note that we’ve now created the same problems of locality that we had with force and energy prediction. What if there are long-range effects on charge and the partial charges assigned by a local network are incorrect? (This isn’t surprising; we already know charges interact with one another over long distances and you can demonstrate effects like this in toy systems.)
Figure 1 from Ko et al, which shows how distant protonation states can impact atom-centered partial charges. I think this example is easy to solve if you use a message-passing GNN for charge prediction, though…
To make long-range effects explicit, many models use charge equilibration (QEq)—see this work from Ko & co-workers and this work from Jacobson & coworkers. Typically a neural network predicts environment-dependent electronegativities and hardnesses, and the atomic charges are determined by minimizing the energy subject to charge conservation. QEq naturally propagates electrostatics to infinite range, but it adds nontrivial overhead—pairwise couplings plus linear algebra that (naïvely) scales as O(N3), although speedups are possiblethrough various approaches—and simple application of charge equilibration also leads to unphysically high polarizability and overdelocalization.
Point-charge approaches like those we’ve been discussing aren’t the only solution. There’s a whole body of work on computing electrostatic interactions from the forcefield world, and many of these techniques can be bolted onto GNNs:
Thürlemann and co-workers used a neural network to predict atom-centered dipoles and quadrupoles, allowing for a much better approximation of the QM electrostatic potential than a simple monopole-only model (like e.g. atom-centered point charges).
Many-body polarization can be accounted for with dipole-induction models or Drude oscillators, both of which model polarization without actually needing to move charge around like QEq does. (These approaches are standard in polarizable forcefields: see this review from Lemkul and co-workers.)
Explicit dispersion corrections, like Grimme’s D3 or D4, can also be added to an NNP. (I’ve always been confused about why you’d do this, though, since dispersion is hardly a long-range force.)
Case Study - BAMBOO
Last year, Sheng Gong and co-workers released BAMBOO, an NNP trained for use modeling battery electrolytes. Since electrostatic interactions are very important to electrolyte solutions, BAMBOO splits their force and energy into three components: (1) a “semi-local” component learned by a graph equivariant transformer, (2) an electrostatic energy with point charges predicted by a separate neural network, and (3) a dispersion correction following the D3 paradigm.
To learn accurate atom-centered partial charges, the team behind BAMBOO used a loss function with four terms. The point-charge model was trained to reproduce:
The overall energy, forces, and virial tensor from DFT (in conjunction with the short-range NNP).
The computed electrostatic potential (from CHELPG calculations).
The computed dipole moment.
The correct charge equilibrium. While Qeq solvers do this by iteratively adjusting charges at inference-time, this becomes expensive; BAMBOO instead adds a charge-equilibration regularization term that teaches the network to predict equilibrated charges, allowing for fast test-time inference. (See Supplemental Information Section A.3 in v4 of the arXiv paper—this section was mysteriously removed from v5.)
With accurate partial charges in hand, the BAMBOO team are able to predict accurate liquid and electrolyte densities, even for unseen molecules. The model’s predictions of ionic conductivity and viscosity are also quite good, which is impressive. BAMBOO uses only low-order equivariant terms (angular momentum of 0 or 1) and can run far more quickly than short-range-only NNPs like Allegro or MACE that require higher-order equivariant terms.
I like the BAMBOO work a lot because it highlights both the potential advantages of adding physics to NNPs—much smaller and more efficient models—but also the challenges of this approach. Physics is complicated, and even getting an NNP to learn atom-centered partial charges correctly requires sophisticated loss-function engineering and orthogonal sources of data (dipole moments and electrostatic potentials).
The biggest argument against explicit inclusion of long-range terms in neural networks, either through local NN prediction or global charge equilibration, is just pragmatism. Explicit handling of electrostatics adds a lot of complexity and doesn’t seem to matter most of the time.
While it’s possible to construct pathological systems where a proper description of long-range electrostatics is crucial, in practice it often seems to be true that purely local NNPs do just fine. This study from Preferred Networks found that adding long-range electrostatics to a GNN (NEquip) didn’t improve performance for most systems, and concluded that “effective cutoff radii can see charge transfer in the present datasets.” Similarly, Marcel Langer recently wrote on X that “most benchmark tasks are easily solved even by short-range message passing”, concluding that “we need more challenging benchmarks… or maybe LR behaviour is simply ‘not that complicated.’”
Still, as the quality of NNPs improves, it’s possible that we’ll start to see more and more cases where the lack of long-range interactions limits the accuracy of the model. The authors of the OMol25 paper speculate that this is the case for their eSEN-based models:
OMol25’s evaluation tasks reveal significant gaps that need to be addressed. Notably, ionization energies/electron affinity, spin-gap, and long range scaling have errors as high as 200-500 meV. Architectural improvements around charge, spin, and long-range interactions are especially critical here.
(For the chemists in the audience, 200–500 meV is approximately 5–12 kcal/mol. This is an alarmingly high error for electron affinity or spin–spin splitting.)
Category 3 - Adding Non-Local Features
The third category of NNPs are those which add an explicit learned non-local term to the network to model long-range effects. This can be seen as a hybrid approach: it’s not as naive as “just make the network bigger,” recognizing that there can be non-trivial non-local effects in chemical systems, but neither does it enforce any particular functional form for these non-local effects.
The above description is pretty vague, which is by design. There are a lot of papers in this area, many of which are quite different: using a self-consistent-field two-model approach (SCFNN), learning long-range effects in reciprocal space, learning non-local representations with equivariant descriptors (LODE) or spherical harmonics (SO3KRATES), learning low-dimensional non-local descriptors (sGDML), or employing long-range equivariant message passing (LOREM). Rather than go through all these papers in depth, I’ve chosen a single example that’s both modern and (I think) somewhat representative.
Case Study - Latent Ewald Summation
In this approach, proposed by Bingqing Cheng in December 2024, a per-atom vector called a “hidden variable” is learned from each atom’s invariant features. Then these variables are combined using long-range Ewald summation and converted to a long-range energy term. At the limit where the hidden variable is a scalar per-atom charge, this just reduces to using Ewald summation with Coulombic point-charge interactions—but with vector hidden variables, considerably more complex long-range interactions can be learned.
This approach (latent Ewald summation, or “LES”) can be combined with basically any short-range NNP architecture—a recent followup demonstrated adding LES to MACE, NequIP, CACE, and CHGNet. They also trained a larger “MACELES” model on the MACE-OFF23 dataset and showed that it outperformed MACE-OFF23(M) on a variety of properties, like organic liquid density:
Entertainingly, the MACE-OFF23 dataset they use here is basically a filtered subset of SPICE that removes all the charged compounds—so there aren’t any ionic interactions here, which are the exact sorts of interactions you’d want long-range forces for (cf. BAMBOO, vide supra). I’m excited to see what happens when you train models like this on large datasets containing charged molecules, and to be able to benchmark models like this myself. (These models aren’t licensed for commercial use, sadly, so we can’t run them through the Rowan benchmark suite.)
There’s something charmingly logical about this third family of approaches. If you think there are non-local effects in your system but you want to use machine learning, simply use an architecture which doesn’t enforce strict locality! Abstractly, representations can be “coarser” for long-distance interactions—while scaling the short-range representation to long ranges can be prohibitively expensive, it’s easy to find a more efficient way to handle long-range interactions. (This is essentially how physics-based schemes like the fast multipole method work.)
Still, training on local representations means that you don’t need to train on large systems, which are often expensive to compute reference data for. As we start to add learned components that only operate at long distances, we need correspondingly larger training data—which becomes very expensive with DFT (and impossible with many functionals). This issue gets more and more acute as the complexity of the learnable long-range component increases—while atom-centered monopole models may be trainable simply with dipole and electrostatic distribution data (e.g. BAMBOO, ibid.), learning more complex long-range forces may require much more data.
Conclusions
I’ve been talking to people about this topic for a while; looking back through Google Calendar, I was surprised to realize that I met Simon Batzner for coffee to talk about long-range forces all the way back in February 2023. I started writing this post in June 2024 (over a year ago), but found myself struggling to finish because I didn’t know what to conclude from all this. Over a year later, I still don’t feel like I can predict what the future holds here—and I’m growing skeptical that anyone else can either.
While virtually everyone in the field agrees that (a) a perfectly accurate model of physics does need to account for long-range forces and (b) today’s models generally don’t account for long-range forces correctly, opinions differ sharply as to how much of a practical limitation this is. Some people see long-range forces as essentially a trivial annoyance that matter only for weird electrolyte-containing interfaces, while others see the mishandling of long-range forces as an insurmountable flaw for this entire generation of NNPs.
New models that account for long-range forces through some clever mechanism are developed to fix this problem.
But a new generation of larger naïve NNPs are also able to fix this problem, so there’s no clear need for long-range physics.
The above pattern is admittedly oversimplified! I’m not aware of any models without explicit long-range forces that can actually predict ionic conductivity like BAMBOO can, although I don’t think the newest OMol25-based models have been tried. But it surprises me that it’s not easier to find cases in which long-range forces are clearly crucial, and this observation makes me slightly more optimistic that simply scaling local GNNs is the way to go (cf. “bitter lessons in chemistry”, which has admittedly become a bit of a meme).
(There’s something nice about keeping everything in learnable parameters, too, even if the models aren’t strictly local. While explicit physics appeals to the chemist in me, I suspect that adding Coulombic terms will make it harder to do clever ML tricks like coarse-graining or transfer learning. So, ceteris paribus, this consideration favors non-physics-based architectures.)
Incorporating explicit long-range interactions, even in ML potentials with an effective cutoff radius of 10 Å, further enhances the model’s generalization capability. These improvements, however, do not translate into systematic changes in predicted physical observables… Including explicit long-range electrostatics also did not improve the accuracy of predicted densities and RDFs of pure liquid water and the NaCl-water mixture…. Similar results were obtained for Ala3 and Crambin, with no evidence that explicit long-range electrostatics improve the accuracy of predicted properties.
This is a beautiful illustration of just how confusing and counterintuitive results in this field can be. It seems almost blatantly obvious that for a given architecture, adding smarter long-range forces should be trivially better than not having long-range forces! But to the surprise and frustration of researchers, real-world tests often fail to show any meaningful improvement. This ambiguity, more than anything else, is what I want to highlight here.
While I’m not smart enough to solve these problems myself, my hope is that this post helps to make our field’s open questions a bit clearer and more legible. I’m certain that there are researchers training models and writing papers right now that will address some of these open questions—and I can’t wait to see what the next 12 months holds.
Thanks to Justin Airas, Simon Batzner, Sam Blau, Liz Decolvaere, Tim Duignan, Alexandre Duval, Gianni de Fabritiis, Ishaan Ganti, Chandler Greenwell, Olexandr Isayev, Yi-Lun Liao, Abhishaike Mahajan, Eli Mann, Djamil Maouene, Alex Mathiasen, Alby Musaelian, Mark Neumann, Sam Norwood, John Parkhill, Justin Smith, Guillem Simeon, Hannes Stärk, Kayvon Tabrizi, Moritz Thürlemann, Zach Ulissi, Jonathan Vandezande, Ari Wagen, Brandon Wood, Wenbin Xu, Zhiao Yu, Yumin Zhang, & Larry Zitnik for helpful discussions on these topics—and Tim Duignan, Sawyer VanZanten, & Ari Wagen for editing drafts of this post. Any errors are mine alone; I have probably forgotten some acknowledgements.