Since the ostensible purpose of organic methodology is to develop reactions that are useful in the real world, the utility of a method is in large part dictated by the accessibility of the starting materials. If a compound is difficult to synthesize or hazardous to work with, then it’s difficult to convince people to use it in a reaction (e.g. most diazoalkanes). Organic chemists are pragmatic, and would usually prefer to run a reaction that starts from a commercial and bench-stable starting material.
For instance, this explains the immense popularity of the Suzuki reaction: although the Neigishi reaction (using organozinc nucleophiles) usually works better for the same substrates, you can buy lots of the organoboron nucleophiles needed to run a Suzuki and leave them lying around without taking any precautions. In contrast, organozinc compounds usually have to be made from the corresponding organolithium/Grignard reagent and used freshly, which is considerably more annoying.
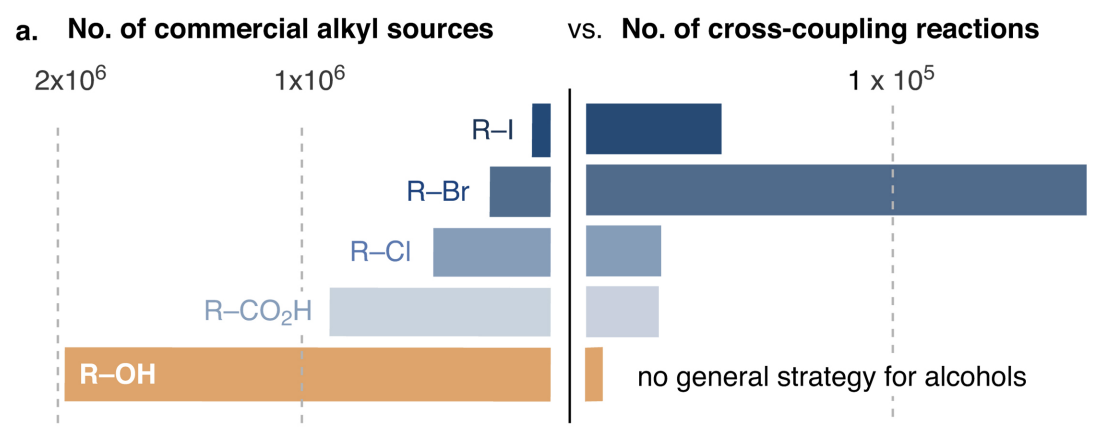
The ideal starting material, then, is one which is commercially available and cheap. In recent years, it’s become popular to advertise new synthetic methods by showing that they work on exceptionally cheap and common functional groups, and in particular to compare the abundance of different functional groups to demonstrate that one starting material is more common than another. To pick just one of many examples, Dave MacMillan used this plot to show why cross-coupling reactions of alcohols were important (ref):
When I saw MacMillan’s talk at MIT last year, I was curious what it would take to make additional graphics like this. The “number of reactions” plot can be made pretty easily from Reaxys, but I’ve always been uncertain how the “number of commercial sources” plots are made: I haven’t seen references listed for these numbers, nor is anything usually found in the Supporting Information.
I decided to take a swing at getting this data myself by analyzing the Mcule "building blocks" database, which contains about 3.5 million compounds. Although Mcule doesn't define what a building block is (at least, not that I can find), it’s likely that their definition is similar to that of ZINC, which defines building blocks as “those catalogs of compounds available in preparative quantities, typically 250 mg or more” (ref). This seems like a reasonable proxy for the sorts of compounds synthetic chemists might use in reactions. I defined patterns to match a bunch of functional groups using SMARTS/SMILES, and then used RDKit to find matches in the Mcule building blocks database. The code can be found on Github, along with the patterns I used.
The results are shown below. As expected, ethers, amines, amides, and alcohols are quite common. Surprisingly, aryl chlorides aren't that much more common than aryl bromides—and, except for aliphatic fluorides, all aliphatic halides are quite rare. Allenes, carbodiimides, and SF5 groups are virtually unheard of (<100 examples).
| Functional Group | Number | Percent |
|---|---|---|
| acid chloride | 6913 | 0.19 |
| alcohol | 1022229 | 28.60 |
| aliphatic bromide | 42018 | 1.18 |
| aliphatic chloride | 70410 | 1.97 |
| aliphatic fluoride | 650576 | 18.20 |
| aliphatic iodide | 3159 | 0.09 |
| alkene | 176484 | 4.94 |
| alkyne | 35577 | 1.00 |
| allene | 99 | 0.00 |
| amide | 518151 | 14.50 |
| anhydride | 1279 | 0.04 |
| aryl bromide | 451451 | 12.63 |
| aryl chloride | 661591 | 18.51 |
| aryl fluoride | 618620 | 17.31 |
| aryl iodide | 216723 | 6.06 |
| azide | 5164 | 0.14 |
| aziridine | 748 | 0.02 |
| carbamate | 127103 | 3.56 |
| carbodiimide | 28 | 0.00 |
| carbonate | 1231 | 0.03 |
| carboxylic acid | 410860 | 11.49 |
| chloroformate | 250 | 0.01 |
| cyclobutane | 195728 | 5.48 |
| cyclopropane | 349455 | 9.78 |
| diene | 10188 | 0.29 |
| difluoromethyl | 163395 | 4.57 |
| epoxide | 5859 | 0.16 |
| ester | 422715 | 11.83 |
| ether | 1434485 | 40.13 |
| isocyanate | 1440 | 0.04 |
| isothiocyanate | 1389 | 0.04 |
| nitrile | 209183 | 5.85 |
| nitro | 126200 | 3.53 |
| pentafluorosulfanyl | 18 | 0.00 |
| primary amine | 904118 | 25.29 |
| secondary amine | 857290 | 23.98 |
| tertiary amine | 609261 | 17.04 |
| trifluoromethoxy | 18567 | 0.52 |
| trifluoromethyl | 455348 | 12.74 |
| urea | 518151 | 14.50 |
| Total | 3574611 | 100.00 |
(Fair warning: I’ve spotchecked a number of the SMILES files generated (also on Github), but I haven’t looked through every molecule, so it’s possible that there are some faulty matches. I wouldn’t consider these publication-quality numbers yet.)
An obvious caveat: there are lots of commercially “rare” functional groups which are easily accessible from more abundant functional groups. For instance, acid chlorides seem uncommon in the above table, but can usually be made from ubiquitous carboxylic acids with e.g. SOCl2. So these data shouldn’t be taken as a proxy for a more holistic measure of synthetic accessibility—they measure commercial availability, that’s all.
What conclusions can we draw from this?
The functional-group-specific SMILES files are in the previously mentioned Github repo, so anyone who wants to e.g. look through all the commercially available alkenes and perform further cheminformatics analyses can do so. I hope the attached code and data helps other chemists perform similar, and better, studies, and that this sort of thinking can be useful for those who are currently engaged in reaction discovery.
Thanks to Eric Jacobsen for helpful conversations about these data.